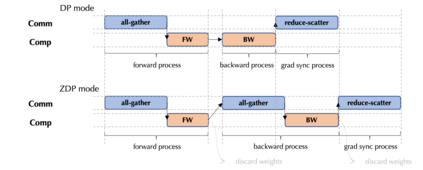
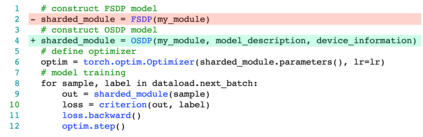
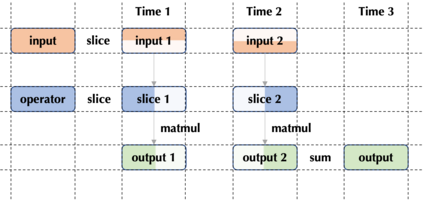
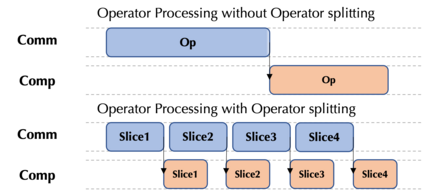
Large-scale deep learning models contribute to significant performance improvements on varieties of downstream tasks. Current data and model parallelism approaches utilize model replication and partition techniques to support the distributed training of ultra-large models. However, directly deploying these systems often leads to sub-optimal training efficiency due to the complex model architectures and the strict device memory constraints. In this paper, we propose Optimal Sharded Data Parallel (OSDP), an automated parallel training system that combines the advantages from both data and model parallelism. Given the model description and the device information, OSDP makes trade-offs between the memory consumption and the hardware utilization, thus automatically generates the distributed computation graph and maximizes the overall system throughput. In addition, OSDP introduces operator splitting to further alleviate peak memory footprints during training with negligible overheads, which enables the trainability of larger models as well as the higher throughput. Extensive experimental results of OSDP on multiple different kinds of large-scale models demonstrate that the proposed strategy outperforms the state-of-the-art in multiple regards.
翻译:现有的数据和模型平行方法利用模型复制和分割技术来支持分布式超大型模型的培训;然而,直接部署这些系统往往导致由于复杂的模型结构和严格的设备内存限制,培训效率低于最佳水平;在本文件中,我们提议采用最佳硬数据平行(OSDP)这一自动化平行培训系统,将数据和模型平行的好处结合起来;鉴于模型描述和装置信息,OSDP在记忆消耗和硬件利用之间作出权衡,从而自动生成分布式计算图并最大限度地扩大整个系统通过投入;此外,OSDP介绍操作者在培训可忽略不计的间接费用期间进行分裂,以进一步减少高峰记忆足迹,从而能够培训更大的模型和较高的吞吐量;OSDP在多种不同类型大型模型上的广泛实验结果表明,拟议的战略在许多方面超过了最新水平。