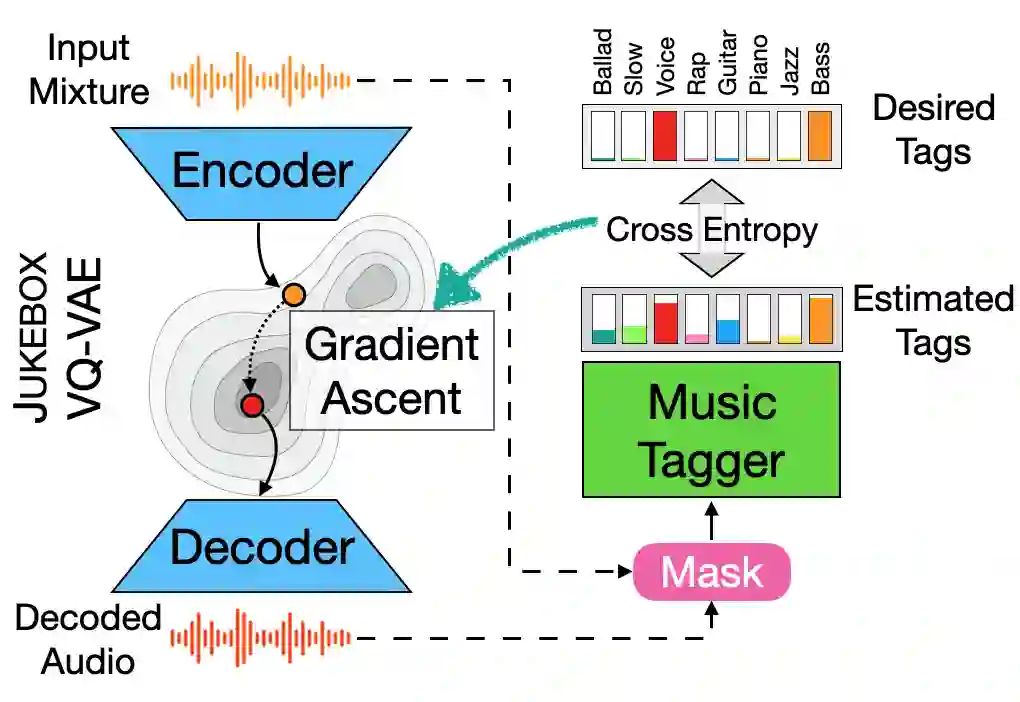
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model's latent space to produce separated sources. We use OpenAI's Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.
翻译:我们展示了一种未经监督的方法,在不进行任何再培训的情况下,重新利用为音乐制作和音乐标记所训练的用于音源分离的深层模型,而不进行再培训。音频生成模型以输入混合物为条件,生成用于生成音频的音频潜在编码。这种生成的音频被反馈到一个经过事先训练的音乐塔格上,从而创建源标签标签。生成音频的标签分发和单独源的预定义分布之间的交叉随机损失被用来指导基因模型(变换)潜在空间中的梯度上升。这个系统不更新基因模型或塔格的重量,而只依靠通过基因模型的潜在空间来生成分离的源。我们使用OpenAI的软盘作为预先训练的基因模型,我们把它与四种经过预先训练的音乐标记器(两个建筑和两个标记数据集)的实验结果用来指导两个源分离数据集的梯度。这个方法可以产生比任何经过测试的受监督或未受监督的系统更广泛的来源的分离估计。这个方法可以产生比任何经过测试的源或未受监督的系统更广泛的各种来源的分离估计数,而仅仅依靠通过基因模型来移动,而只依靠通过基因模型来产生分离的移动,而只能将产生一个巨大的和远未开发的磁系。这个工作点与大型和远未开发的大型的大型和未开发的大型的磁源的潜力。