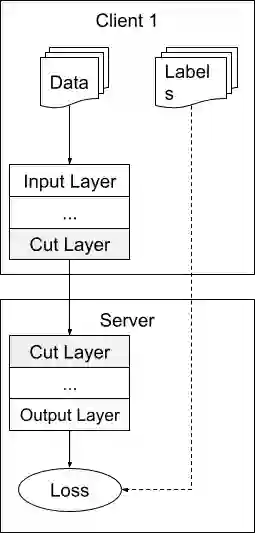
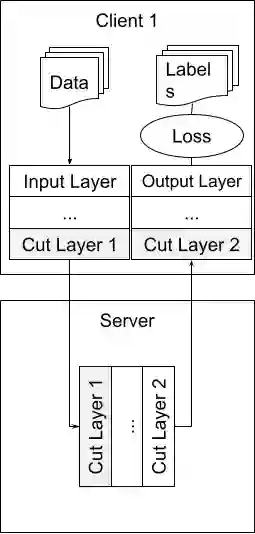
Deep Learning has established in the latest years as a successful approach to address a great variety of tasks. Healthcare is one of the most promising field of application for Deep Learning approaches since it would allow to help clinicians to analyze patient data and perform diagnoses. However, despite the vast amount of data collected every year in hospitals and other clinical institutes, privacy regulations on sensitive data - such as those related to health - pose a serious challenge to the application of these methods. In this work, we focus on strategies to cope with privacy issues when a consortium of healthcare institutions needs to train machine learning models for identifying a particular disease, comparing the performances of two recent distributed learning approaches - Federated Learning and Split Learning - on the task of Automated Chest X-Ray Diagnosis. In particular, in our analysis we investigated the impact of different data distributions in client data and the possible policies on the frequency of data exchange between the institutions.
翻译:近些年来,深入学习是处理各种任务的成功方法,保健是深层学习方法最有希望的应用领域之一,因为它可以帮助临床医生分析病人的数据和进行诊断,然而,尽管医院和其他临床机构每年收集大量数据,但敏感数据的隐私条例(例如与健康有关的条例)对采用这些方法构成严重挑战。在这项工作中,当一个保健机构联合会需要培训机器学习模型以确定特定疾病时,我们注重处理隐私问题的战略,比较最近两个分布式学习方法(联邦学习和分门别类学习)在自动化Chest X-Ray诊断任务方面的表现,特别是在我们的分析中,我们调查了客户数据的不同数据分配的影响以及各机构之间数据交换频率的可能政策。