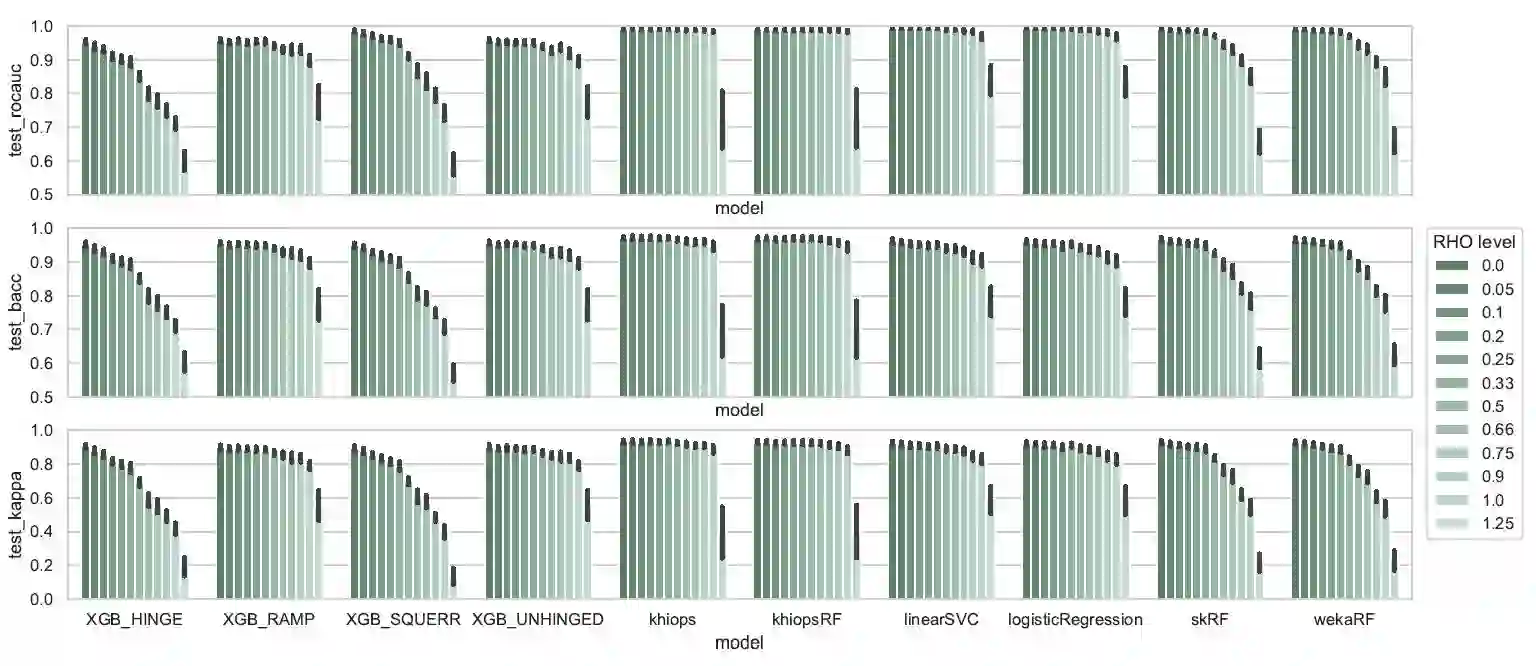
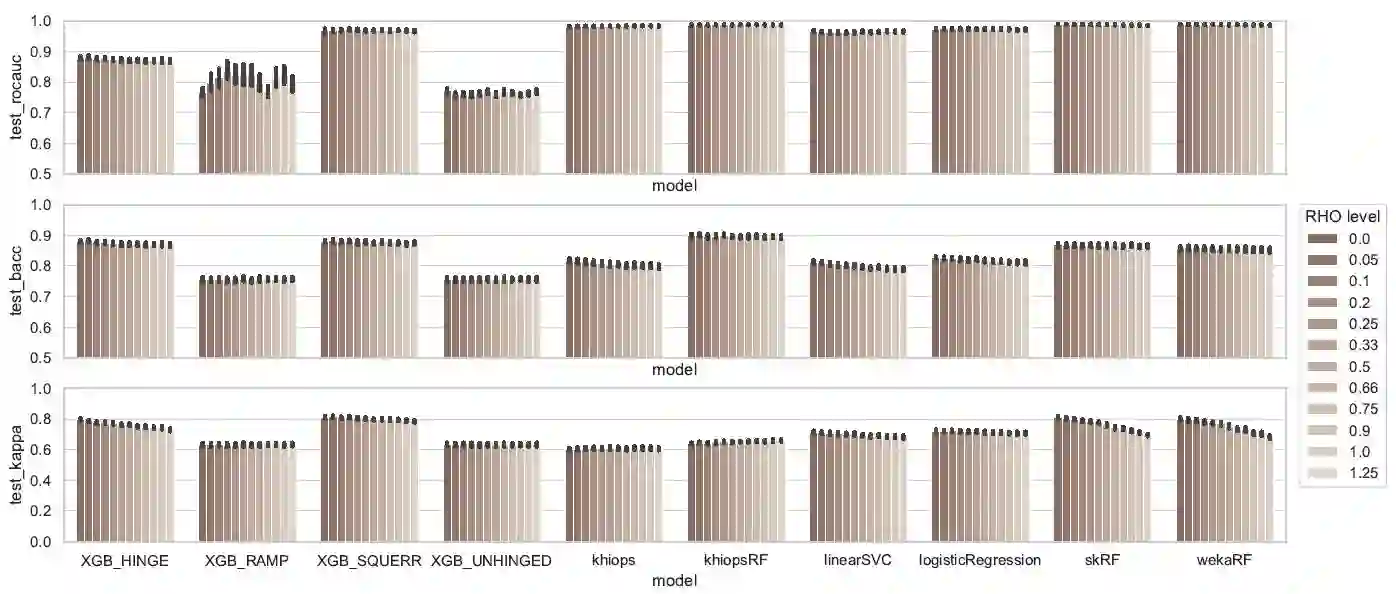
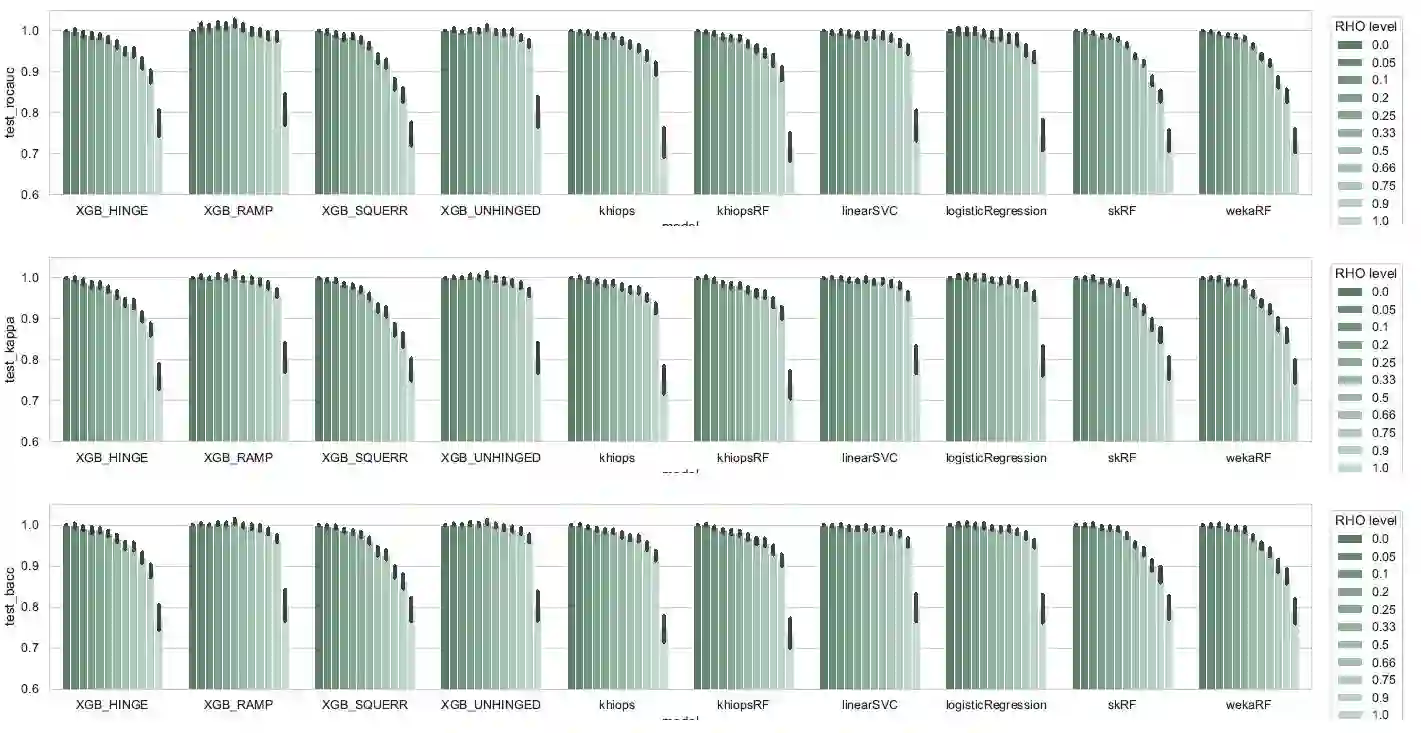
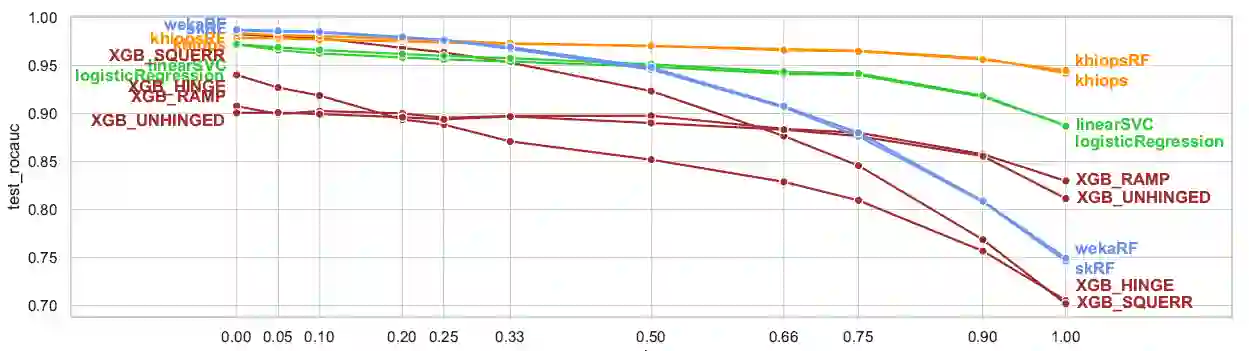
In some industrial applications such as fraud detection, the performance of common supervision techniques may be affected by the poor quality of the available labels : in actual operational use-cases, these labels may be weak in quantity, quality or trustworthiness. We propose a benchmark to evaluate the natural robustness of different algorithms taken from various paradigms on artificially corrupted datasets, with a focus on noisy labels. This paper studies the intrinsic robustness of some leading classifiers. The algorithms under scrutiny include SVM, logistic regression, random forests, XGBoost, Khiops. Furthermore, building on results from recent literature, the study is supplemented with an investigation into the opportunity to enhance some algorithms with symmetric loss functions.
翻译:在一些工业应用中,如欺诈检测,通用监督技术的运用可能受到现有标签质量差的影响:在实际操作使用个案中,这些标签在数量、质量或可信度方面可能薄弱。我们提出了一个基准,以评价从人工腐蚀数据集的各种范式中得出的不同算法的自然稳健性,重点是噪音标签。本文研究一些主要分类者的内在稳健性。所审查的算法包括SVM、物流回归、随机森林、XGBoost、Khiops。此外,根据最近文献的结果,研究还补充了对加强某些具有对称损失功能的算法的机会的调查。