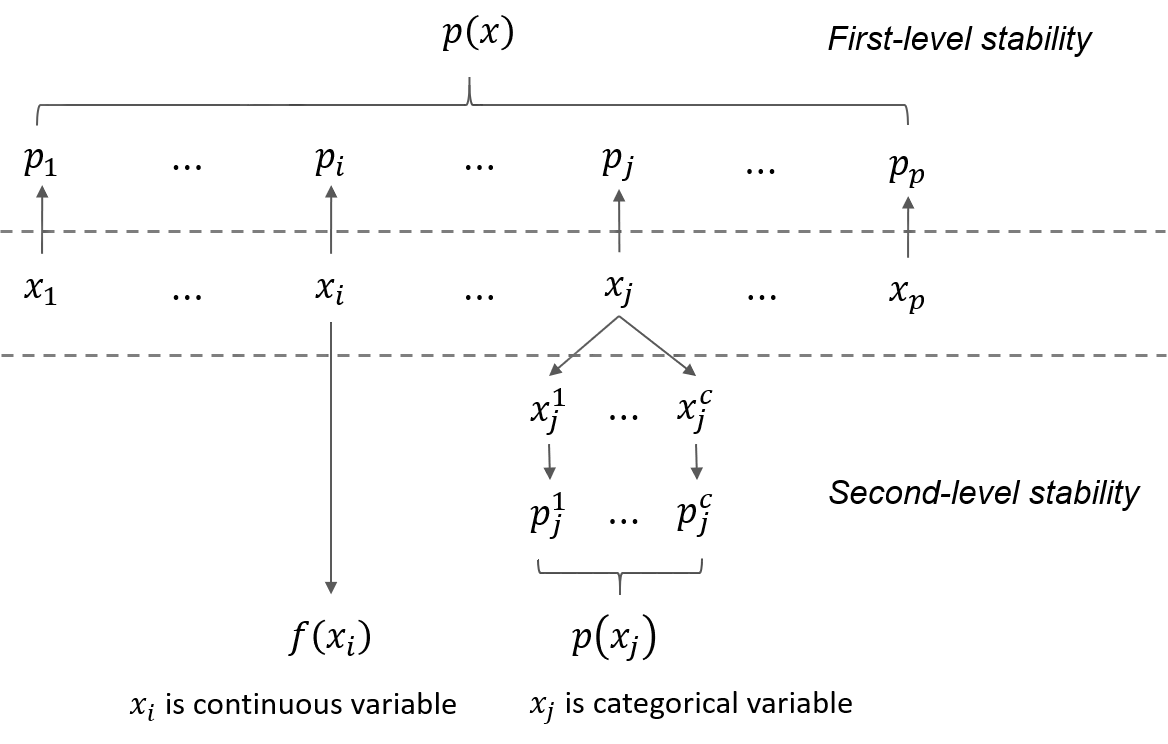
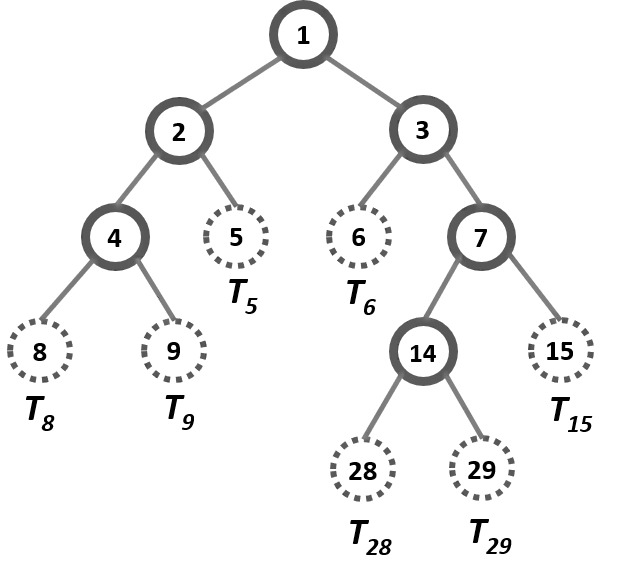
Black-box machine learning models are criticized as lacking interpretability, although they tend to have good prediction accuracy. Knowledge Distillation (KD) is an emerging tool to interpret the black-box model by distilling its knowledge into a transparent model. With well-known advantages in interpretation, decision tree is a competitive candidate of the transparent model. However, theoretical or empirical understanding for the decision tree generated from KD process is limited. In this paper, we name this kind of decision tree the distillation decision tree (DDT) and lay the theoretical foundations for tree structure stability which determines the validity of DDT's interpretation. We prove that the structure of DDT can achieve stable (convergence) under some mild assumptions. Meanwhile, we develop algorithms for stabilizing the induction of DDT, propose parallel strategies for improving algorithm's computational efficiency, and introduce a marginal principal component analysis method for overcoming the curse of dimensionality in sampling. Simulated and real data studies justify our theoretical results, validate the efficacy of algorithms, and demonstrate that DDT can strike a good balance between model's prediction accuracy and interpretability.
翻译:黑盒机器学习模型被批评为缺乏可解释性,尽管它们往往具有良好的预测准确性。知识蒸馏(KD)是一个新兴的工具,通过将它的知识提炼成透明的模型来解释黑盒模型。在解释方面具有众所周知的优势,决策树是透明模型的竞争性候选人。然而,对KD过程产生的决策树的理论或经验理解有限。在本文中,我们将这种决策树命名为蒸馏决定树(DDT),并为树结构稳定性奠定理论基础,从而决定滴滴涕解释的有效性。我们证明,在一些温和的假设下,滴滴涕的结构可以实现稳定(趋同 ) 。与此同时,我们制定了稳定滴滴涕诱发过程的算法,提出提高计算效率的平行战略,并引入边际主要分析方法,以克服取样中对维度的诅咒。模拟和真实的数据研究证明我们的理论结果是正确的,验证算法的有效性,并证明滴滴涕可以在模型的预测准确性和可解释性之间取得良好的平衡。