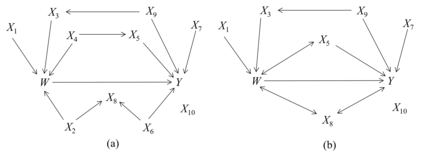
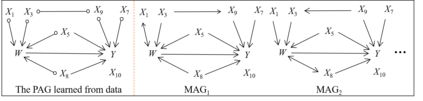
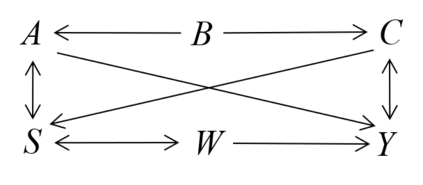
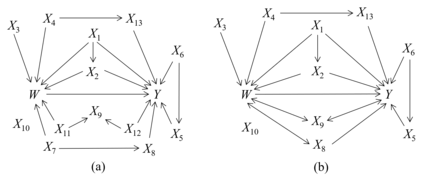
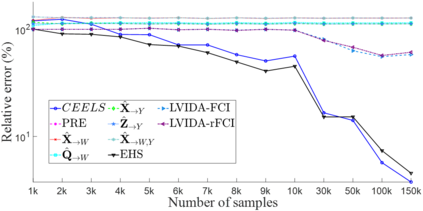
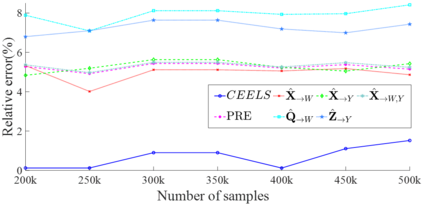
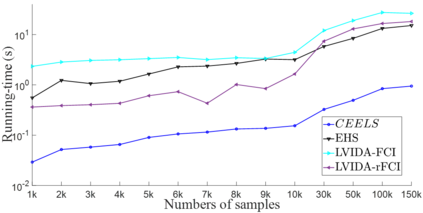
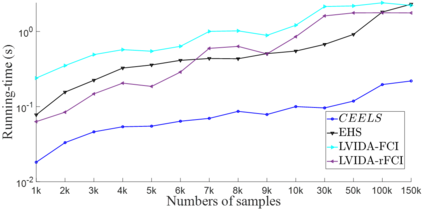
Causal effect estimation from observational data is a challenging problem, especially with high dimensional data and in the presence of unobserved variables. The available data-driven methods for tackling the problem either provide an estimation of the bounds of a causal effect (i.e. nonunique estimation) or have low efficiency. The major hurdle for achieving high efficiency while trying to obtain unique and unbiased causal effect estimation is how to find a proper adjustment set for confounding control in a fast way, given the huge covariate space and considering unobserved variables. In this paper, we approach the problem as a local search task for finding valid adjustment sets in data. We establish the theorems to support the local search for adjustment sets, and we show that unique and unbiased estimation can be achieved from observational data even when there exist unobserved variables. We then propose a data-driven algorithm that is fast and consistent under mild assumptions. We also make use of a frequent pattern mining method to further speed up the search of minimal adjustment sets for causal effect estimation. Experiments conducted on extensive synthetic and real-world datasets demonstrate that the proposed algorithm outperforms the state-of-the-art criteria/estimators in both accuracy and time-efficiency.
翻译:从观测数据中获得的因果关系估计是一个具有挑战性的问题,特别是在高维数据和存在未观测的变量的情况下。现有数据驱动的解决问题方法要么提供因果效应(即非单一估算)的界限估计,要么低效率。在试图从观测数据获得独特和不偏不倚的因果关系估计的同时,实现高效的主要障碍是如何找到一种适当的调整,以便快速地进行混乱控制,考虑到巨大的共变空间和未观测的变量。在本文中,我们将这一问题作为寻找数据中有效调整数据集的本地搜索任务来对待。我们建立理论以支持当地对调整数据集的搜索,我们表明即使存在未观测的变量,也可以从观测数据中得出独特和不偏颇的估计。我们然后提出一种数据驱动的算法,在温和的假设下是快速和一致的。我们还利用一种经常模式的采矿方法,以进一步加快寻找因果估计的最低限度调整数据集。对广泛的合成和真实世界数据集进行的实验表明,拟议的算法在精确度方面都超过了州/地方的精确度标准。