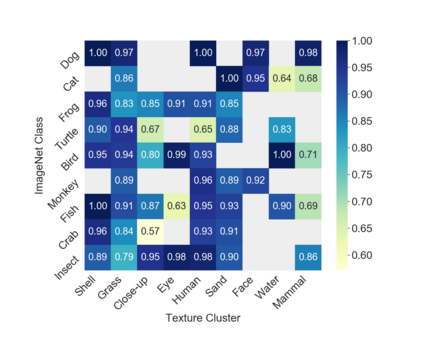
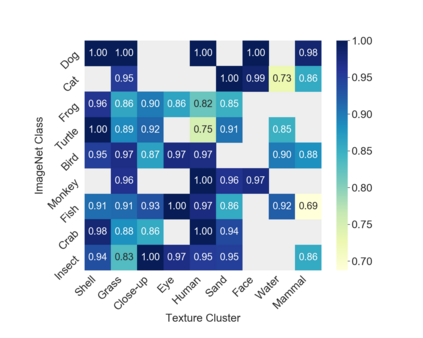
Many machine learning algorithms are trained and evaluated by splitting data from a single source into training and test sets. While such focus on in-distribution learning scenarios has led to interesting advancement, it has not been able to tell if models are relying on dataset biases as shortcuts for successful prediction (e.g., using snow cues for recognising snowmobiles). Such biased models fail to generalise when the bias shifts to a different class. The cross-bias generalisation problem has been addressed by de-biasing training data through augmentation or re-sampling, which are often prohibitive due to the data collection cost (e.g., collecting images of a snowmobile on a desert) and the difficulty of quantifying or expressing biases in the first place. In this work, we propose a novel framework to train a de-biased representation by encouraging it to be different from a set of representations that are biased by design. This tactic is feasible in many scenarios where it is much easier to define a set of biased representations than to define and quantify bias. We demonstrate the efficacy of our method across a variety of synthetic and real-world biases. Our experiments and analyses show that the method discourages models from taking bias shortcuts, resulting in improved generalisation.
翻译:许多机器学习算法都是通过将数据从单一来源分为培训和测试组来进行训练和评价的。虽然这种对分布式学习情景的这种关注导致了令人感兴趣的进展,但尚不能说明模型是否依赖数据集偏向作为成功预测的捷径(例如,使用雪球标分雪车)。这种偏向模式在偏向转向不同类别时无法概括。交叉偏向的概括问题通过通过扩大或再取样来消除偏见的培训数据来解决,由于数据收集成本(例如,收集沙漠上的雪行动图象)以及首先难以量化或表达偏见,因此往往令人望而却步。在这项工作中,我们提出了一个新的框架来训练一种不偏向的代表性,鼓励它不同于因设计偏向而偏向的一组表述。这种策略在许多情况下是可行的,在界定一套偏向的表述比定义和量化偏向性容易得多。我们展示了我们方法在各种合成和现实世界的偏向性方面的效率。我们进行实验和分析时提出了一个新的框架,通过鼓励它与设计偏向不同的表达方式。我们从一般的偏向性中得出了一种偏向性的偏向性的方法。