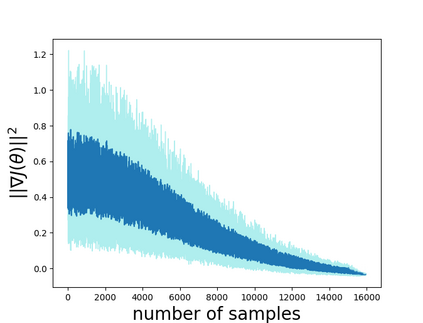
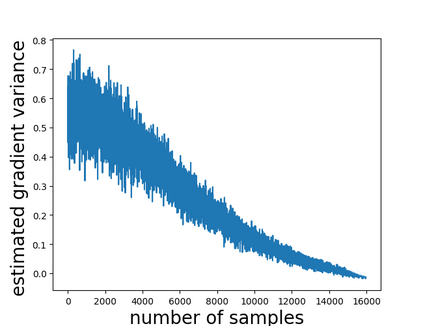
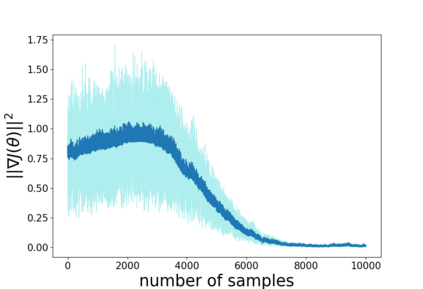
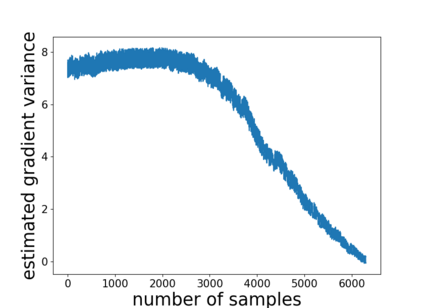
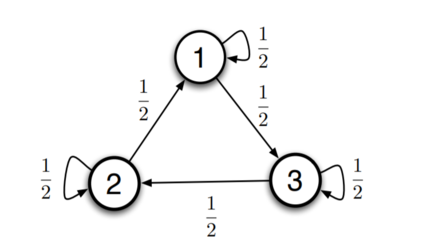
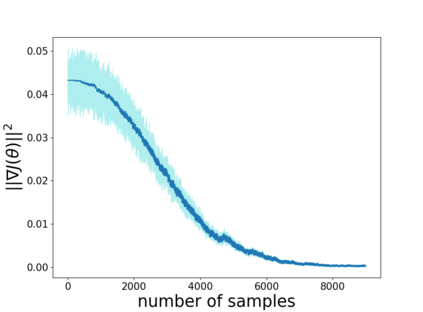
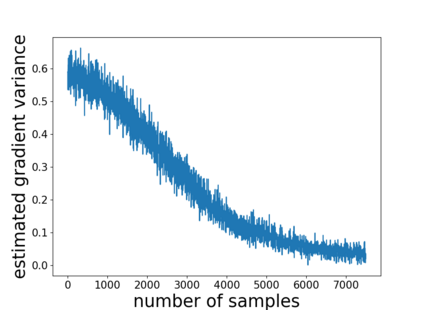
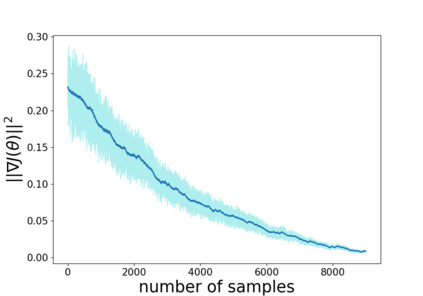
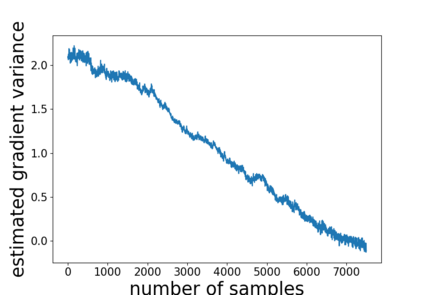
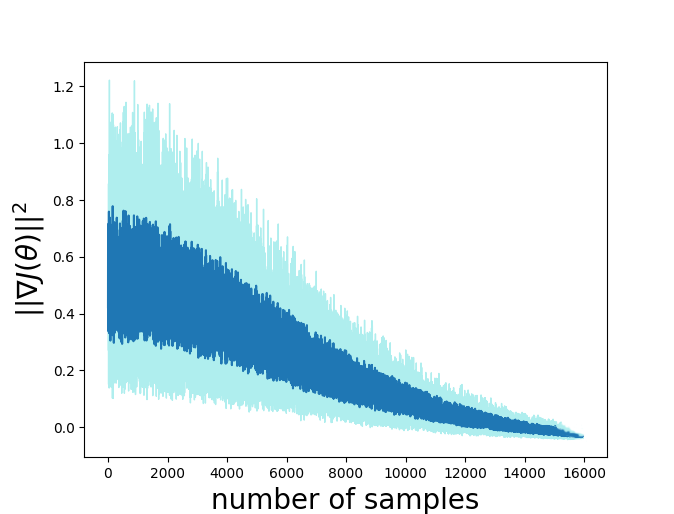
Temporal-difference learning with gradient correction (TDC) is a two time-scale algorithm for policy evaluation in reinforcement learning. This algorithm was initially proposed with linear function approximation, and was later extended to the one with general smooth function approximation. The asymptotic convergence for the on-policy setting with general smooth function approximation was established in [bhatnagar2009convergent], however, the finite-sample analysis remains unsolved due to challenges in the non-linear and two-time-scale update structure, non-convex objective function and the time-varying projection onto a tangent plane. In this paper, we develop novel techniques to explicitly characterize the finite-sample error bound for the general off-policy setting with i.i.d.\ or Markovian samples, and show that it converges as fast as $\mathcal O(1/\sqrt T)$ (up to a factor of $\mathcal O(\log T)$). Our approach can be applied to a wide range of value-based reinforcement learning algorithms with general smooth function approximation.
翻译:使用梯度校正(TDC) 的时差学习是一种用于强化学习中政策评价的两种时间尺度算法。 这种算法最初用线性函数近似法提出,后来扩大到一般平滑函数近近似法。 在[bhatnagar2009convergent] 中,以一般平滑函数近近似法确定政策环境中的无光度趋同,但由于非线性和两次时间级更新结构、非康维克斯目标函数和对正切平面的时间对流投的挑战,有限抽样分析仍未解析。 在本文中,我们开发了新技术,以 i.d.\ 或Markovian 样本明确确定一般离层设置的定点缩差,并显示它与 $mathcal O(1/\ sqrt T) 相融合的速度( 最高为 $\mathcal O(\log T) 的系数) 。 我们的方法可以适用于一系列基于价值的强化学习算法, 以及一般平稳功能近似 。