
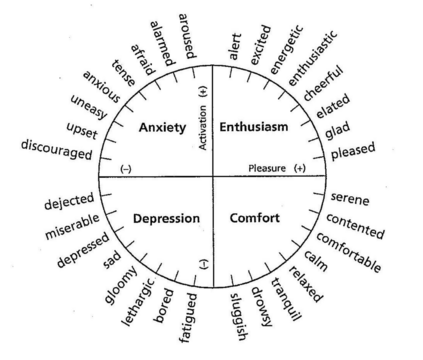
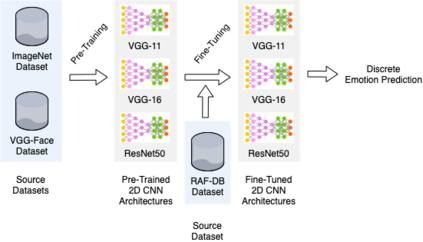
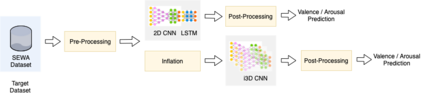
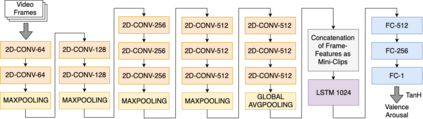
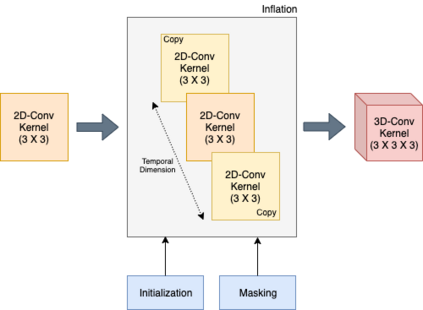
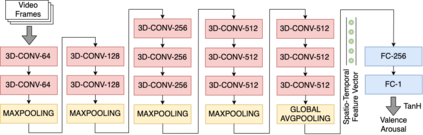
Facial expressions are one of the most powerful ways for depicting specific patterns in human behavior and describing human emotional state. Despite the impressive advances of affective computing over the last decade, automatic video-based systems for facial expression recognition still cannot handle properly variations in facial expression among individuals as well as cross-cultural and demographic aspects. Nevertheless, recognizing facial expressions is a difficult task even for humans. In this paper, we investigate the suitability of state-of-the-art deep learning architectures based on convolutional neural networks (CNNs) for continuous emotion recognition using long video sequences captured in-the-wild. This study focuses on deep learning models that allow encoding spatiotemporal relations in videos considering a complex and multi-dimensional emotion space, where values of valence and arousal must be predicted. We have developed and evaluated convolutional recurrent neural networks combining 2D-CNNs and long short term-memory units, and inflated 3D-CNN models, which are built by inflating the weights of a pre-trained 2D-CNN model during fine-tuning, using application-specific videos. Experimental results on the challenging SEWA-DB dataset have shown that these architectures can effectively be fine-tuned to encode the spatiotemporal information from successive raw pixel images and achieve state-of-the-art results on such a dataset.
翻译:面部表达方式是描述人类行为和描述人类情绪状态的具体模式的最有力方法之一。尽管过去十年来情感计算取得了令人印象深刻的进展,但是用于面部表达识别的自动视频系统仍然无法正确处理个人面部表达以及跨文化和人口方面的差异。然而,承认面部表达方式是人类甚至难以完成的任务。在本文中,我们调查了基于超动神经网络的先进深层学习结构是否适合使用在网上捕捉的长视频序列来持续识别情感。这项研究侧重于深层学习模式,这些模式允许视频中进行线性情感关系编码,考虑到复杂的多维度情感空间,必须预测价值和令人振奋的价值观。我们开发并评估了共振的循环神经网络,其中结合了2D-CNNs和长短程短时间单元,以及3D-CNN模型的膨胀,这些模型是通过在微调过程中将经过训练的2D-CNN模型的重量加增而建立的。在微调整过程中,利用应用特定特定图像空间空间的图像空间,这些连续的实验结果能够对SEV-CA的原始数据结构产生挑战性结果。
相关内容

Source: Apple - iOS 8

