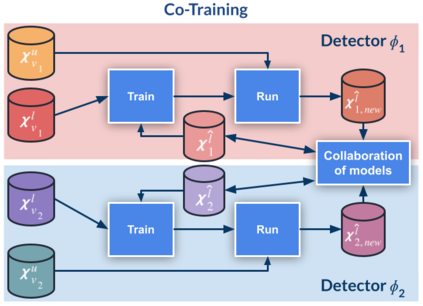
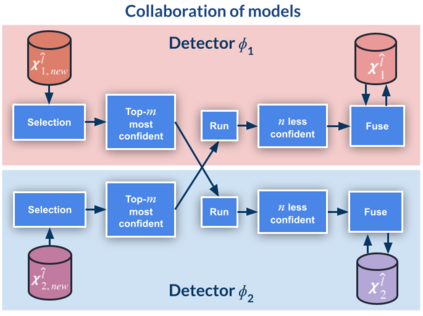
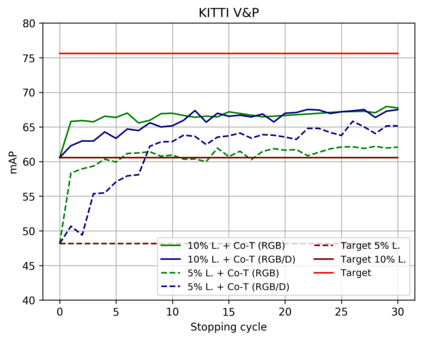
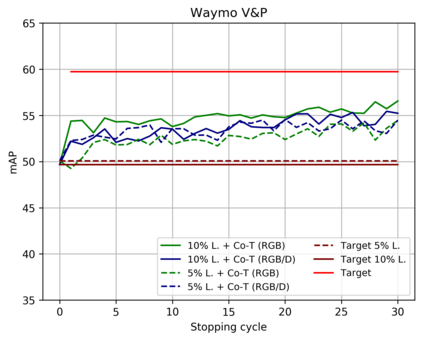
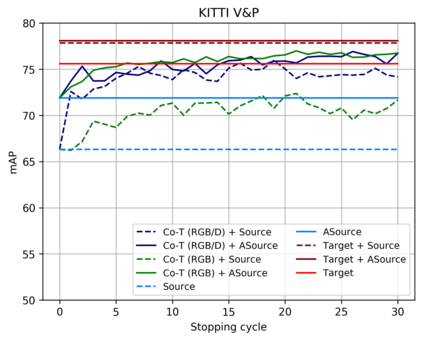
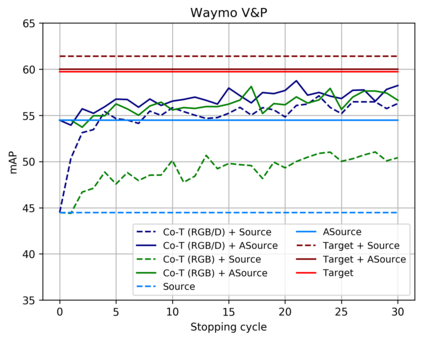
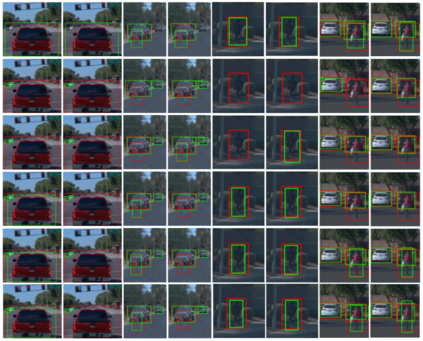
Top-performing computer vision models are powered by convolutional neural networks (CNNs). Training an accurate CNN highly depends on both the raw sensor data and their associated ground truth (GT). Collecting such GT is usually done through human labeling, which is time-consuming and does not scale as we wish. This data labeling bottleneck may be intensified due to domain shifts among image sensors, which could force per-sensor data labeling. In this paper, we focus on the use of co-training, a semi-supervised learning (SSL) method, for obtaining self-labeled object bounding boxes (BBs), i.e., the GT to train deep object detectors. In particular, we assess the goodness of multi-modal co-training by relying on two different views of an image, namely, appearance (RGB) and estimated depth (D). Moreover, we compare appearance-based single-modal co-training with multi-modal. Our results suggest that in a standard SSL setting (no domain shift, a few human-labeled data) and under virtual-to-real domain shift (many virtual-world labeled data, no human-labeled data) multi-modal co-training outperforms single-modal. In the latter case, by performing GAN-based domain translation both co-training modalities are on pair; at least, when using an off-the-shelf depth estimation model not specifically trained on the translated images.
翻译:高性能计算机视觉模型由神经神经网络(CNNs)驱动。 培训一个准确的CNN 高度取决于原始感应数据及其相关的地面真相(GT) 。 收集这种GT通常通过人类标签进行,这种标签费时且不按我们的意愿进行。 这种标记瓶颈的数据可能因图像传感器的域变换而强化,这可能会迫使每个传感器的数据标签。 在本文中,我们侧重于使用联合培训,即半监督的深度学习(SSL)方法,以获取自标对象约束框(BBs),即GT来培训深度物体探测器。 特别是,我们通过依赖两种不同的图像观点来评估多模式共同培训的好坏, 即外观( RGB) 和估计深度(D) 。 此外,我们将基于外观的单一模式联合培训与多式数据标签。 我们的结果表明,在标准 SSL 设置( 没有域变换, 没有几个人标签数据) 和在虚拟到现实域域内, 使用一个特定的翻译模式的多式数据变换 G。