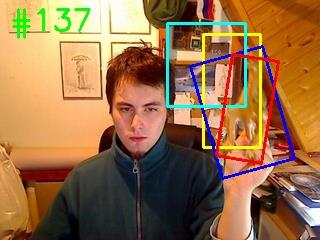
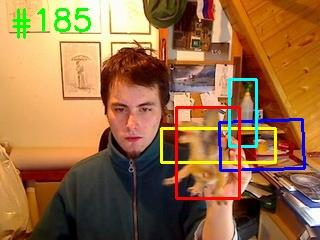
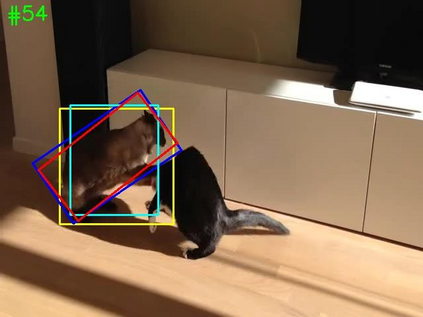
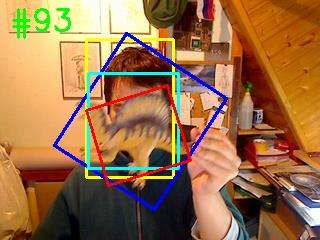
Siamese-based trackers have achieved excellent performance on visual object tracking. However, the target template is not updated online, and the features of the target template and search image are computed independently in a Siamese architecture. In this paper, we propose Deformable Siamese Attention Networks, referred to as SiamAttn, by introducing a new Siamese attention mechanism that computes deformable self-attention and cross-attention. The self attention learns strong context information via spatial attention, and selectively emphasizes interdependent channel-wise features with channel attention. The cross-attention is capable of aggregating rich contextual inter-dependencies between the target template and the search image, providing an implicit manner to adaptively update the target template. In addition, we design a region refinement module that computes depth-wise cross correlations between the attentional features for more accurate tracking. We conduct experiments on six benchmarks, where our method achieves new state of-the-art results, outperforming the strong baseline, SiamRPN++ [24], by 0.464->0.537 and 0.415->0.470 EAO on VOT 2016 and 2018.
翻译:以暹粒为基础的跟踪器在视觉物体跟踪方面表现良好。 但是,目标模板没有在线更新,目标模板和搜索图像的特征在暹粒结构中独立计算。 在本文中,我们建议采用一个新的暹粒关注机制,将可变的暹粒关注网络称为暹粒关注网络,以计算可变自留和交叉关注。自我关注通过空间关注学习了强有力的背景信息,有选择地强调具有频道关注的、相互依存的频道功能。交叉关注能够将目标模板和搜索图像之间的丰富背景相互依存性汇总起来,为适应性更新目标模板提供隐含的方式。此外,我们设计了一个区域改进模块,将注意力特征之间的深度交叉关联进行计算,以便更准确地跟踪。我们在六个基准上进行了实验,我们的方法在其中取得了新的艺术成果,超过了强大的基线,SiamRPN+++ [24],在2016年和2018年的VOT和2018年的SiamRPN++[24]中,以0.464-37和0.415-0470 EAOEAO。