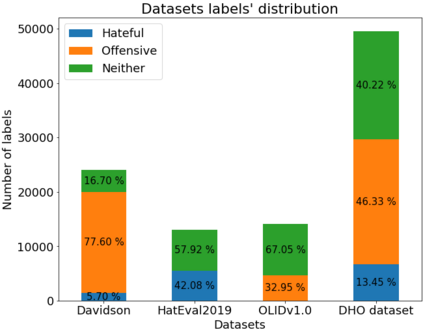
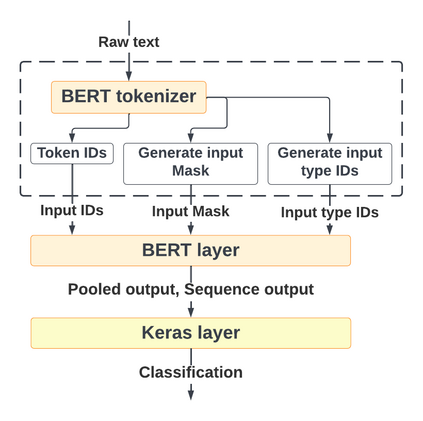
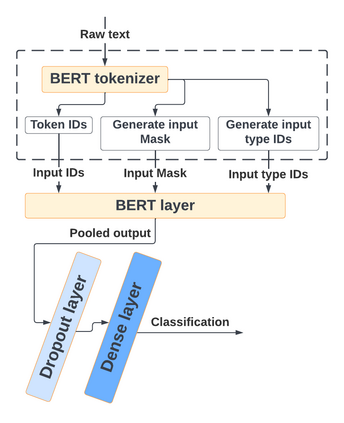
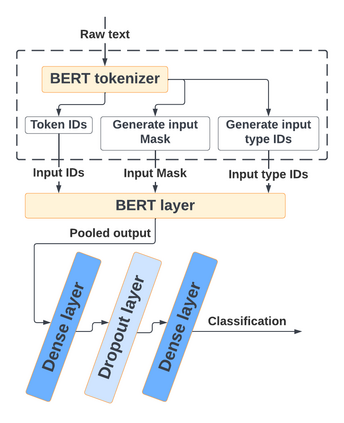
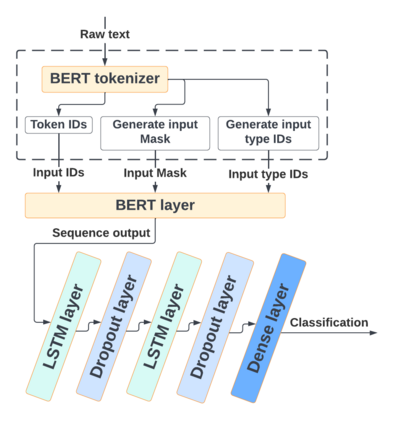
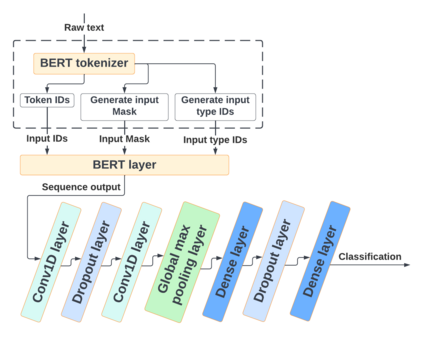
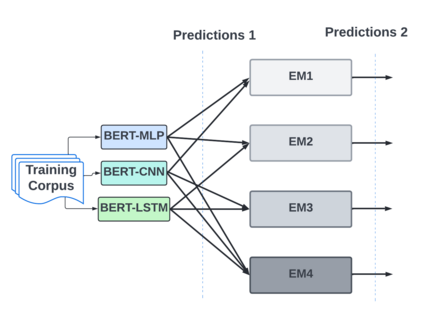
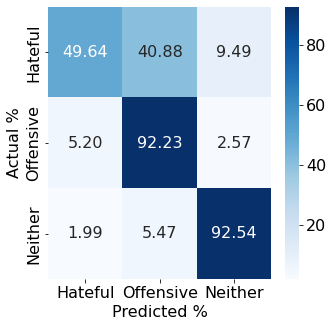
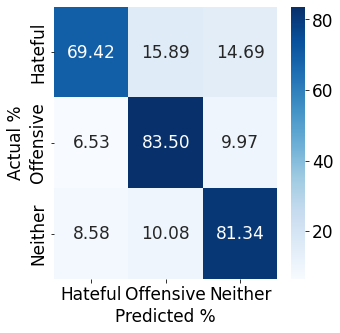
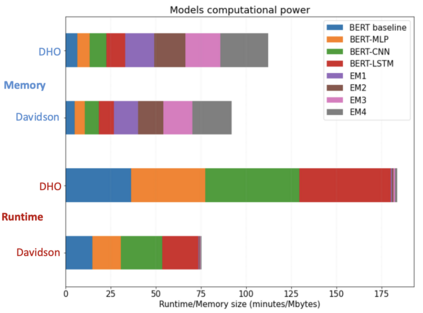
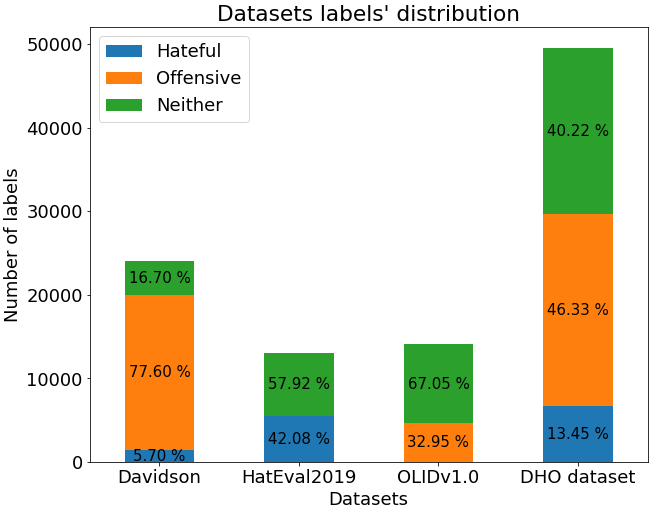
With the freedom of communication provided in online social media, hate speech has increasingly generated. This leads to cyber conflicts affecting social life at the individual and national levels. As a result, hateful content classification is becoming increasingly demanded for filtering hate content before being sent to the social networks. This paper focuses on classifying hate speech in social media using multiple deep models that are implemented by integrating recent transformer-based language models such as BERT, and neural networks. To improve the classification performances, we evaluated with several ensemble techniques, including soft voting, maximum value, hard voting and stacking. We used three publicly available Twitter datasets (Davidson, HatEval2019, OLID) that are generated to identify offensive languages. We fused all these datasets to generate a single dataset (DHO dataset), which is more balanced across different labels, to perform multi-label classification. Our experiments have been held on Davidson dataset and the DHO corpora. The later gave the best overall results, especially F1 macro score, even it required more resources (time execution and memory). The experiments have shown good results especially the ensemble models, where stacking gave F1 score of 97% on Davidson dataset and aggregating ensembles 77% on the DHO dataset.
翻译:随着在线社交媒体提供的通信自由,仇恨言论已日益产生。这导致了影响个人和国家层面社会生活的网络冲突。因此,在发送到社交网络之前,对过滤仇恨内容日益要求仇恨内容进行分类。本文件侧重于使用多种深度模型对社交媒体中的仇恨言论进行分类,这些模型是通过整合最近基于变压器的语言模型(如BERT)和神经网络等而实施的。为了改进分类性能,我们用包括软投票、最大价值、硬投票和堆叠在内的多种混合技术对分类进行了评估。我们使用了三种公开提供的Twitter数据集(Davidson、HatEval2019、OLID),这些数据集被用来识别攻击性语言。我们将所有这些数据集结合起来,以生成一个单一的数据集(DHO数据集),该数据集在不同标签中更加平衡。我们一直在对Davidson数据集和DHO Cora进行实验。后来,我们给出了最佳的总体结果,特别是F1宏观评分,甚至需要更多的资源(时间执行和记忆),用于识别攻击性语言。我们把这些数据集结合了所有这些数据集,特别是97 %的DSOB的排名。