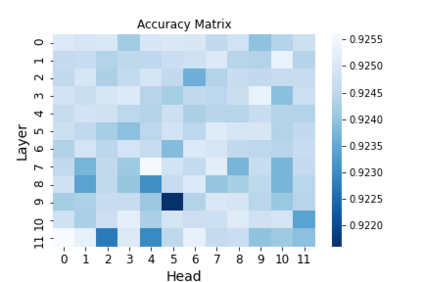
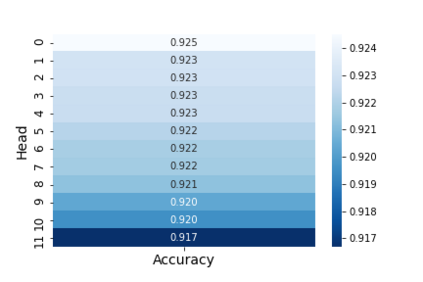
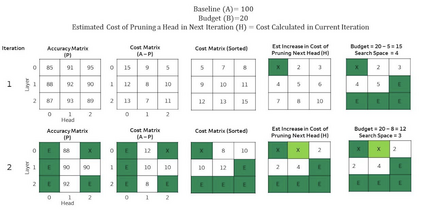
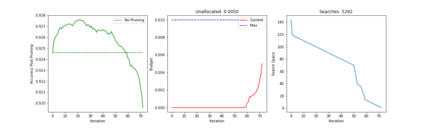
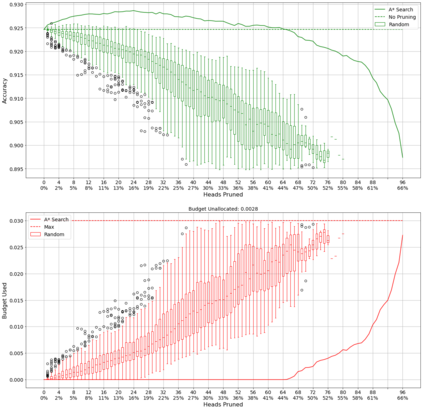
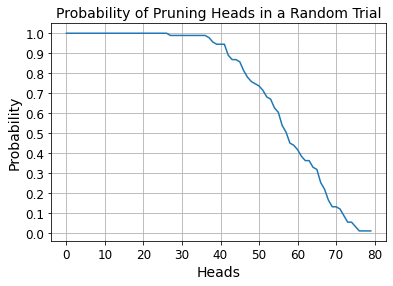
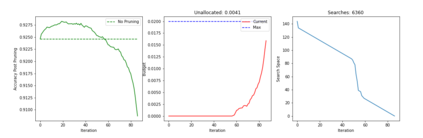
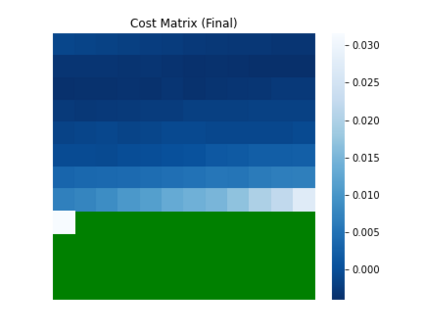
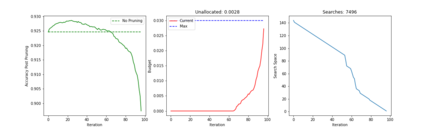
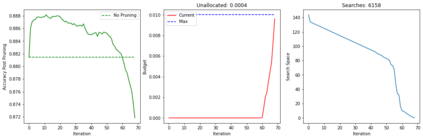
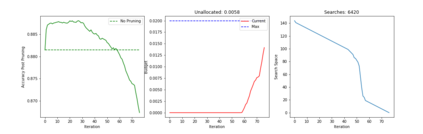
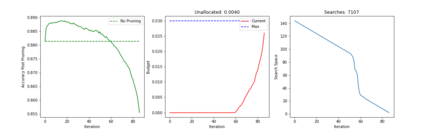
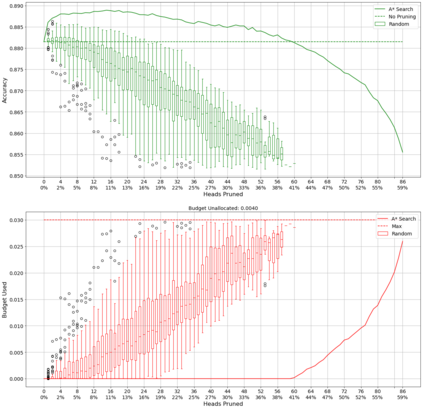
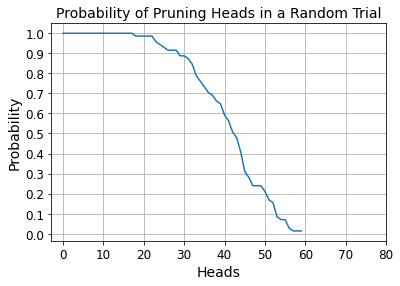
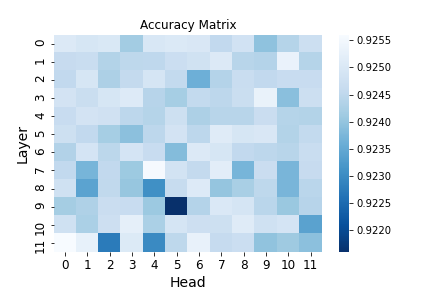
Recent years have seen a growing adoption of Transformer models such as BERT in Natural Language Processing and even in Computer Vision. However, due to the size, there has been limited adoption of such models within resource-constrained computing environments This paper proposes novel pruning algorithms to compress transformer models by eliminating redundant Attention Heads. We apply the A* search algorithm to obtain a pruned model with minimal accuracy guarantees. Our results indicate that the method could eliminate as much as 40% of the attention heads in the BERT transformer model with almost no loss in accuracy.
翻译:近年来,人们越来越多地采用变换模型,例如在自然语言处理甚至计算机愿景中采用BERT。然而,由于规模小,在资源受限制的计算环境中采用这种模型有限。本文建议采用新的修剪算法,通过消除冗余的“注意”头来压缩变压器模型。我们应用A*搜索算法来获得一个精细的模型,保证其精确度最小。我们的结果表明,这种方法可以消除BERT变压器模型中40%的受关注对象,而且几乎没有任何误差。