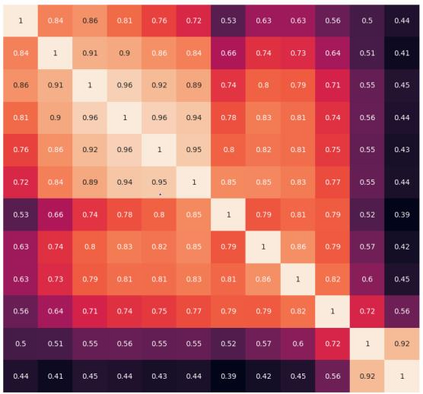
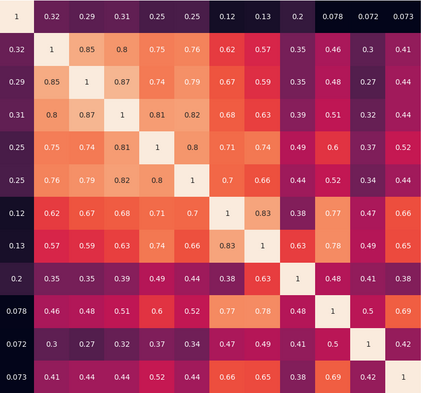
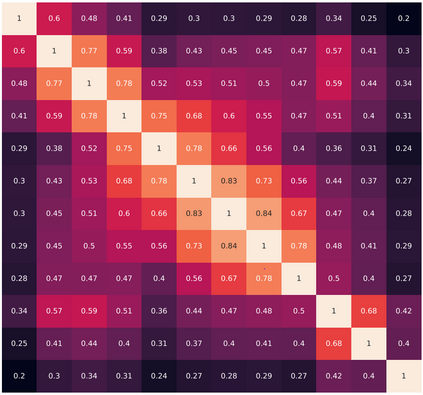
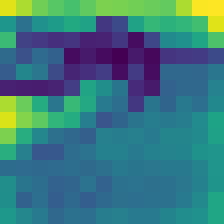This work aims to improve the efficiency of vision transformers (ViT). While ViTs use computationally expensive self-attention operations in every layer, we identify that these operations are highly correlated across layers -- a key redundancy that causes unnecessary computations. Based on this observation, we propose SkipAt, a method to reuse self-attention computation from preceding layers to approximate attention at one or more subsequent layers. To ensure that reusing self-attention blocks across layers does not degrade the performance, we introduce a simple parametric function, which outperforms the baseline transformer's performance while running computationally faster. We show the effectiveness of our method in image classification and self-supervised learning on ImageNet-1K, semantic segmentation on ADE20K, image denoising on SIDD, and video denoising on DAVIS. We achieve improved throughput at the same-or-higher accuracy levels in all these tasks.
翻译:这项工作的目的是提高视觉变压器(VIT)的效率。 Vits在每一层使用成本高昂的计算自控操作时,我们发现这些操作在各层之间高度相关 -- -- 这是造成不必要计算的关键冗余。 基于这一观察,我们提议SkippAt, 这是一种从前层再利用自控计算方法, 以大致关注其后一层或多层。 为了确保在各层之间重新使用自控区块不会降低性能, 我们引入了一个简单的参数函数, 它比基线变压器的性能要好得多, 而计算速度要快。 我们展示了我们在图像Net-1K、 ad20K 的语义分解、 SIDD 图像分解和 DAVIS 视频分解方面的方法的有效性。 我们在所有这些任务中提高同一或更高的精度水平的吞吐量。