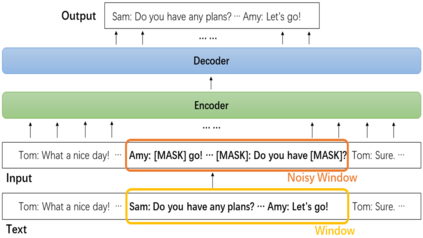
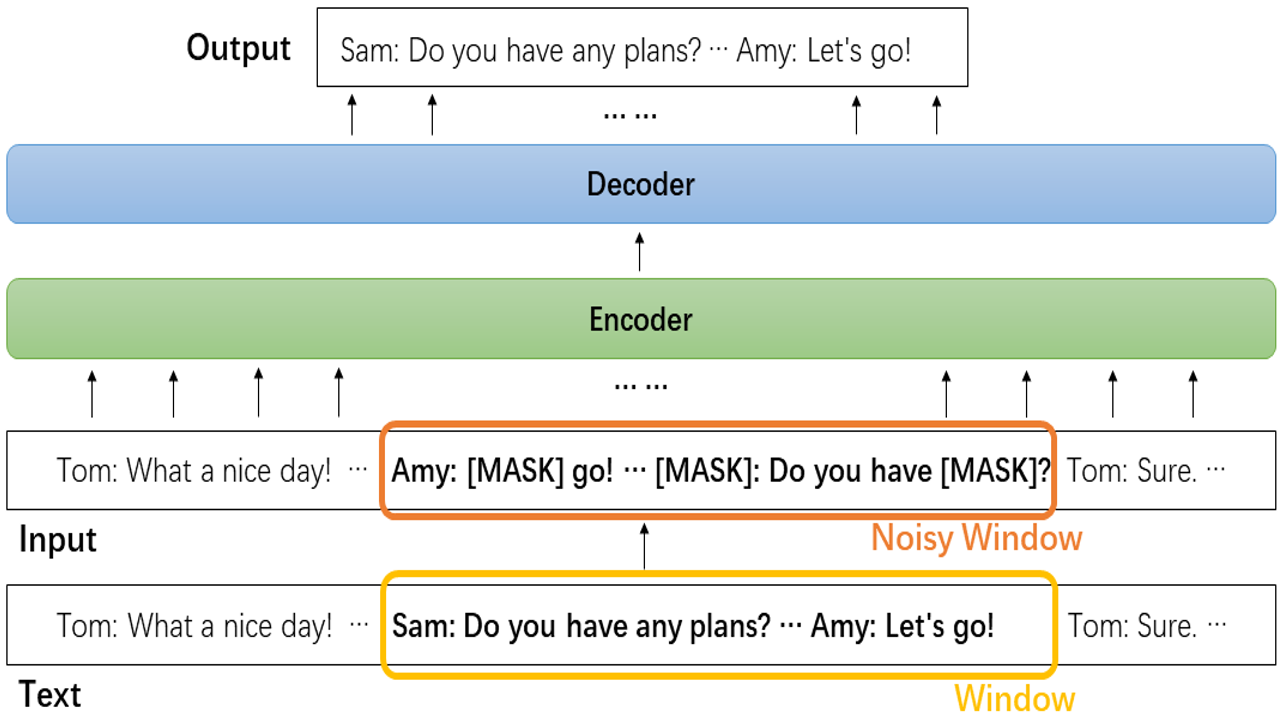
Dialogue is an essential part of human communication and cooperation. Existing research mainly focuses on short dialogue scenarios in a one-on-one fashion. However, multi-person interactions in the real world, such as meetings or interviews, are frequently over a few thousand words. There is still a lack of corresponding research and powerful tools to understand and process such long dialogues. Therefore, in this work, we present a pre-training framework for long dialogue understanding and summarization. Considering the nature of long conversations, we propose a window-based denoising approach for generative pre-training. For a dialogue, it corrupts a window of text with dialogue-inspired noise, and guides the model to reconstruct this window based on the content of the remaining conversation. Furthermore, to process longer input, we augment the model with sparse attention which is combined with conventional attention in a hybrid manner. We conduct extensive experiments on five datasets of long dialogues, covering tasks of dialogue summarization, abstractive question answering and topic segmentation. Experimentally, we show that our pre-trained model DialogLM significantly surpasses the state-of-the-art models across datasets and tasks.
翻译:现有研究主要以一对一的方式关注短期对话情景。然而,在现实世界中,多人互动,例如会议或访谈,往往超过几千字。仍然缺乏相应的研究和有力的工具来理解和处理这种长期对话。因此,在这项工作中,我们提出了一个长期对话理解和总结的培训前框架。考虑到长期对话的性质,我们提议一种基于窗口的分层方法来进行基因化培训前的训练。在对话中,它腐蚀了一个带有对话激发的噪音的文本窗口,并指导基于剩余对话内容重建这一窗口的模式。此外,为了处理更长时间的投入,我们以分散的注意力来扩大模型,同时以混合的方式将常规关注结合起来。我们在五个长期对话的数据集上进行了广泛的实验,涵盖对话的总结、抽象问题解答和专题分解等任务。实验时,我们展示了我们预先培训的模型DialogLM大大超越了跨数据集和任务的最新模型。