【文本摘要】Text Summarization文本摘要与注意力机制

整理:泛音
公众号:深度学习视觉
什么是NLP中的文本摘要
文本摘要目前大致可以分为两种类型:
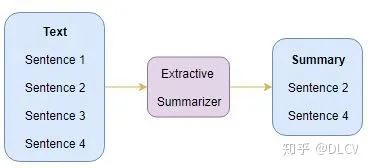
Extractive Summarization:重要内容、语句的提取。
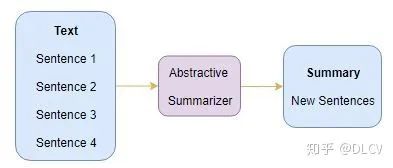
Abstractive Summarization:文本总结。
Extractive Summarization
Abstractive Summarization
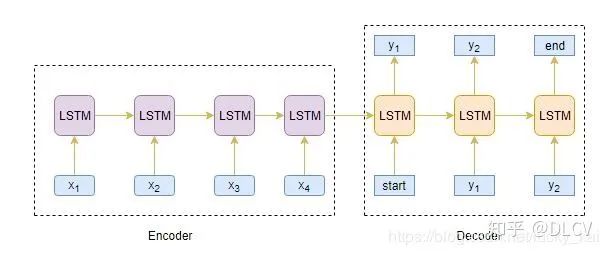
Seq2Seq模型
机器翻译任务中,输入是连续文本序列,输出也是连续文本序列。
Encoder编码器
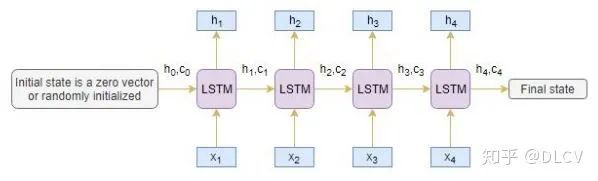
上一个时间step的隐藏层h1与记忆单元层c1将会用来初始化Decoder。
Decoder解码器
解码器可以在给定前一个单词的情况下预测序列中的下一个单词。解码器的初始输入是编码器最后一步的结果。
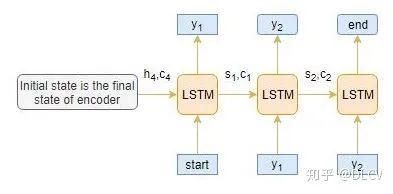
Deocder的工作流程
下图显示了每一个time step下Decoder是如何工作的。
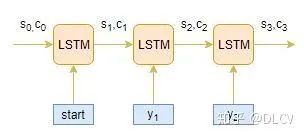
推理部分
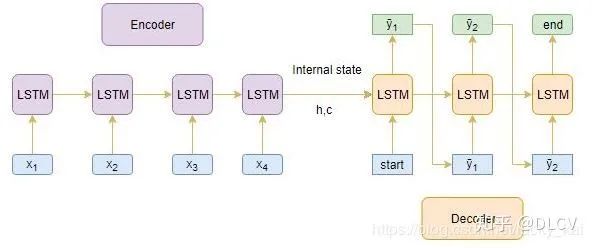
Encoder整个输入序列,并且用Encoder最后一个状态结果来初始化Decoder。
将[start]作为输入传递给解码器Decoder。
使用通过Encoder初始化过的Decoder运行一个time stpe。
输出将是下一个单词的概率,将选择概率最大的单词。
这个预测的单词将会在下一时间Step中作为输入。并且通过当前状态更新内部参数。
重复步骤3-5,直到生成[end]或达到目标序列的最大长度。
Encoder-Decoder结构的局限性
注意力机制
需要编码的序列[x1,x2,x3,x4,x5,x6,x7]
Source sequence: “Which sport do you like the most?需要解码的序列[y1,y2,y3]
Target sequence: I love cricket.
Global Attention and Local Attention
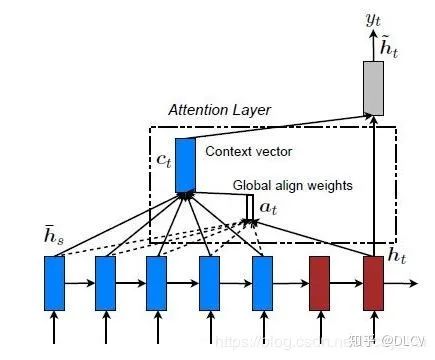
编码器的隐藏层中,仅有部分参与attention计算上下文。
本文最终采用全局注意力机制。(只是添加了注意力机制,编码的固定长度依然需要固定。所以实战中需要通过数据确定一个合适的长度数值。短了无法表达文本内容,长了会造成计算资源浪费。)
实战
数据表述
数据涵盖了超过10年的时间,包括截至2012年10月的所有〜500,000条评论。这些评论包括产品,用户信息,评级,纯文本评论和摘要。它还包括来自所有其他亚马逊类别的评论。
数据处理
评论文本处理
将所有字母小写;
移除HTML标签;
Contraction mapping;
移除(‘s);
删除括号内的内容(觉得括号里面的内容解释说明不重要);
消除标点符号和特殊字符;
删除停用词;
删除低频词;
摘要文本处理
数据分布
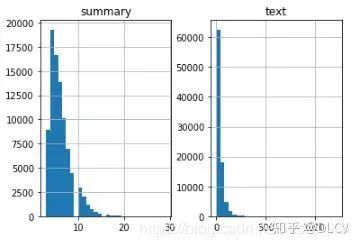
建立Tokenizer
模型建立
我们可以选择是否让LSTM在每个时间步都会生成隐藏状态h和记忆单元状态c。
选择LSTM是否仅生成最后一个时间步的隐藏状态h和记忆单元状态c。
选择LSTM相互堆叠提高模型效果。
选择双向LSTM,可以双向处理文本数据,获取更加丰富的上下文信息。
使用beam search strategy代替贪婪方法argmax。
根据BLEU分数评估模型的性能。
可以选择指针生成网络,
因为整数序列采用独热编码的方式,所以损失函数采用了稀疏交叉熵,对内存友好。
数学理解注意力机制
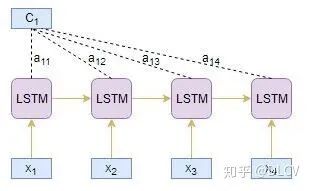
 。用这个分数表示源文本中的第j步单词与目标文本中第i步单词的关联度。可以用hj与si来计算这个分数值
。用这个分数表示源文本中的第j步单词与目标文本中第i步单词的关联度。可以用hj与si来计算这个分数值






参考:
Comprehensive Guide to Text Summarization using Deep Learning in Python
https://www.analyticsvidhya.com/blog/2019/06/comprehensive-guide-text-summarization-using-deep-learning-python/?utm_source=blog&utm_medium=understanding-transformers-nlp-state-of-the-art-models
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




