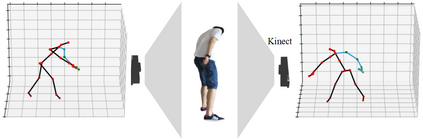
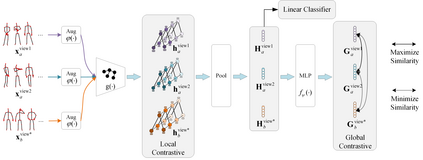
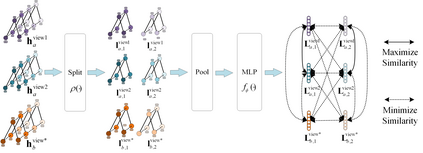
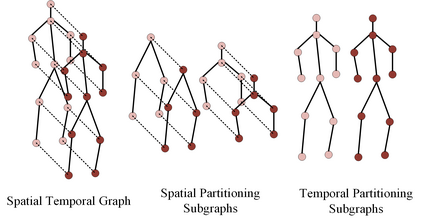
Skeleton-based human action recognition has been drawing more interest recently due to its low sensitivity to appearance changes and the accessibility of more skeleton data. However, even the 3D skeletons captured in practice are still sensitive to the viewpoint and direction gave the occlusion of different human-body joints and the errors in human joint localization. Such view variance of skeleton data may significantly affect the performance of action recognition. To address this issue, we propose in this paper a new view-invariant representation learning approach, without any manual action labeling, for skeleton-based human action recognition. Specifically, we leverage the multi-view skeleton data simultaneously taken for the same person in the network training, by maximizing the mutual information between the representations extracted from different views, and then propose a global-local contrastive loss to model the multi-scale co-occurrence relationships in both spatial and temporal domains. Extensive experimental results show that the proposed method is robust to the view difference of the input skeleton data and significantly boosts the performance of unsupervised skeleton-based human action methods, resulting in new state-of-the-art accuracies on two challenging multi-view benchmarks of PKUMMD and NTU RGB+D.
翻译:最近,由于对外观变化的敏感度较低,而且可以获取更多骨骼数据,基于皮肤的人类行动认识最近引起了更多的关注,然而,实际上所捕捉的三维骨骼对于观点和方向仍然敏感,导致人类-身体不同结合的排斥和人类共同定位的错误。骨骼数据的这种差异可能会大大影响行动认知的绩效。为了解决这一问题,我们在本文件中建议采用新的视觉-差异代表性学习方法,不使用任何手动行动标签,用于基于骨骼的人类行动认识。具体地说,我们利用在网络培训中同时为同一人提供的多维观骨骼数据,最大限度地利用从不同观点得到的演示之间的相互信息,然后提出全球-局部对比损失,以模拟空间和时空领域的多尺度共生关系。广泛的实验结果表明,拟议方法对输入骨骼数据的视角差异十分有力,大大提升了未经超超额的骨骼人类行动方法的性能,从而在具有挑战性的两种多视角基准上的NKMUM和NMUM+RDUR上产生了新的状态和艺术的反光谱。