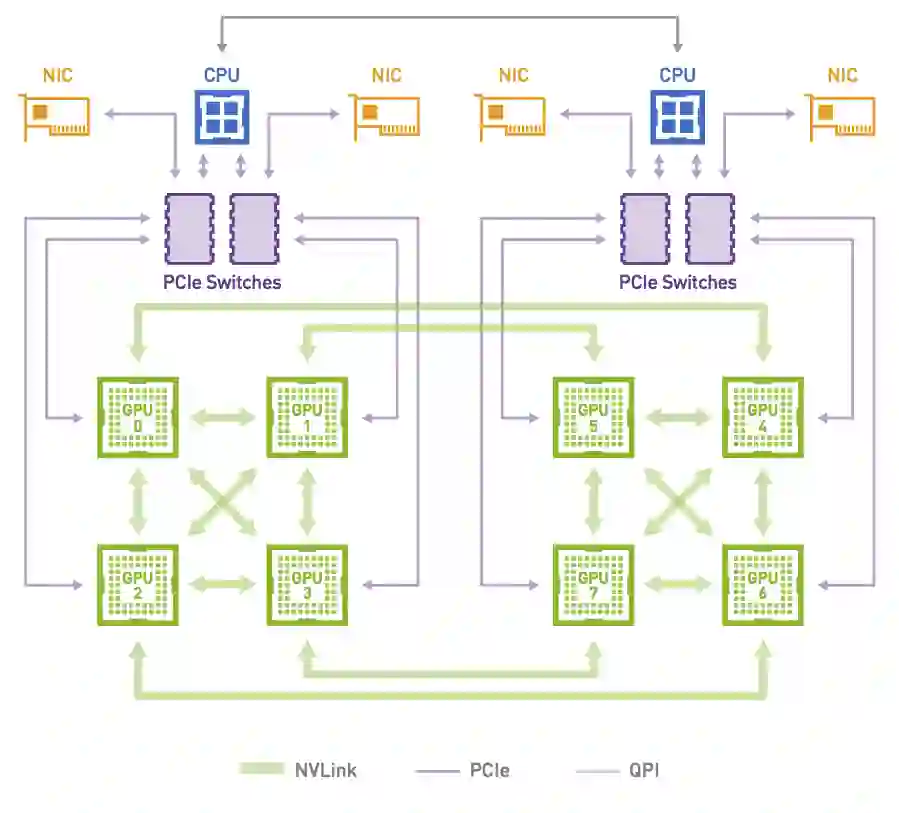
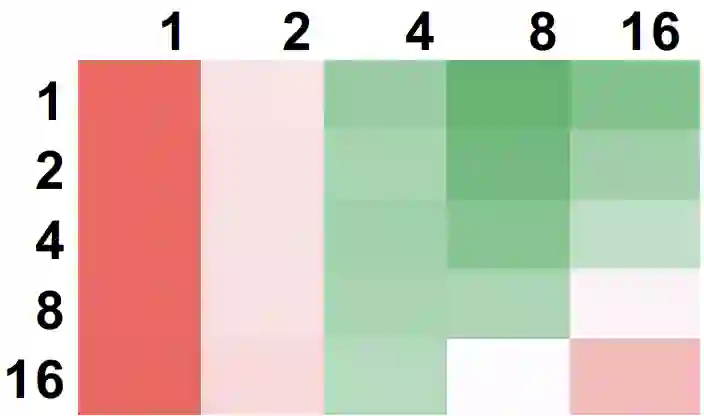
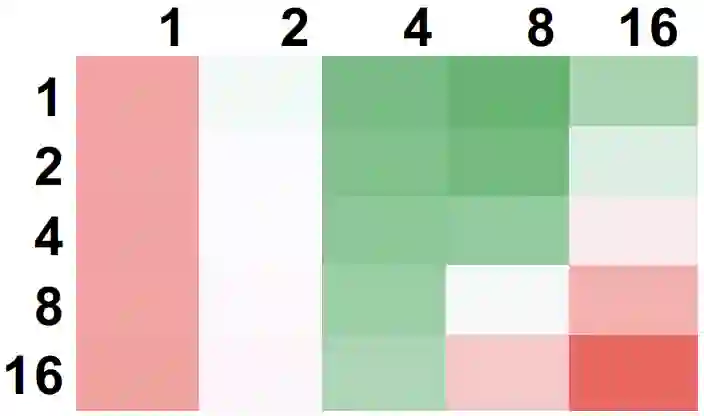
The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.
翻译:图形神经网络(GNNs)的输入图纸规模的扩大突出了对使用多GPU平台的需求。然而,现有的多GPU GNN解决方案由于计算不平衡和通信效率低而表现不佳。为此,我们提议MGG,这是一个创新系统设计,通过GPU-中心软件管道加速多GPU平台上的GNS。MGG探索通过微微分计算-通信管道将远程记忆存取延缓隐藏到GNN工作量的潜力。具体地说,MGG推出管道-觉悟工作量管理战略和混合数据布局设计,以便利通信-计算重叠。MGGG采用优化的管道-中心内核内核。它包括高效的GPU内核操作管内衬和专门的内存设计和优化,以提高数据访问性能。此外,MGGGGG还采用轻度分析模型和优化超速超速超速超速超速超速的GNNNNS-MUD