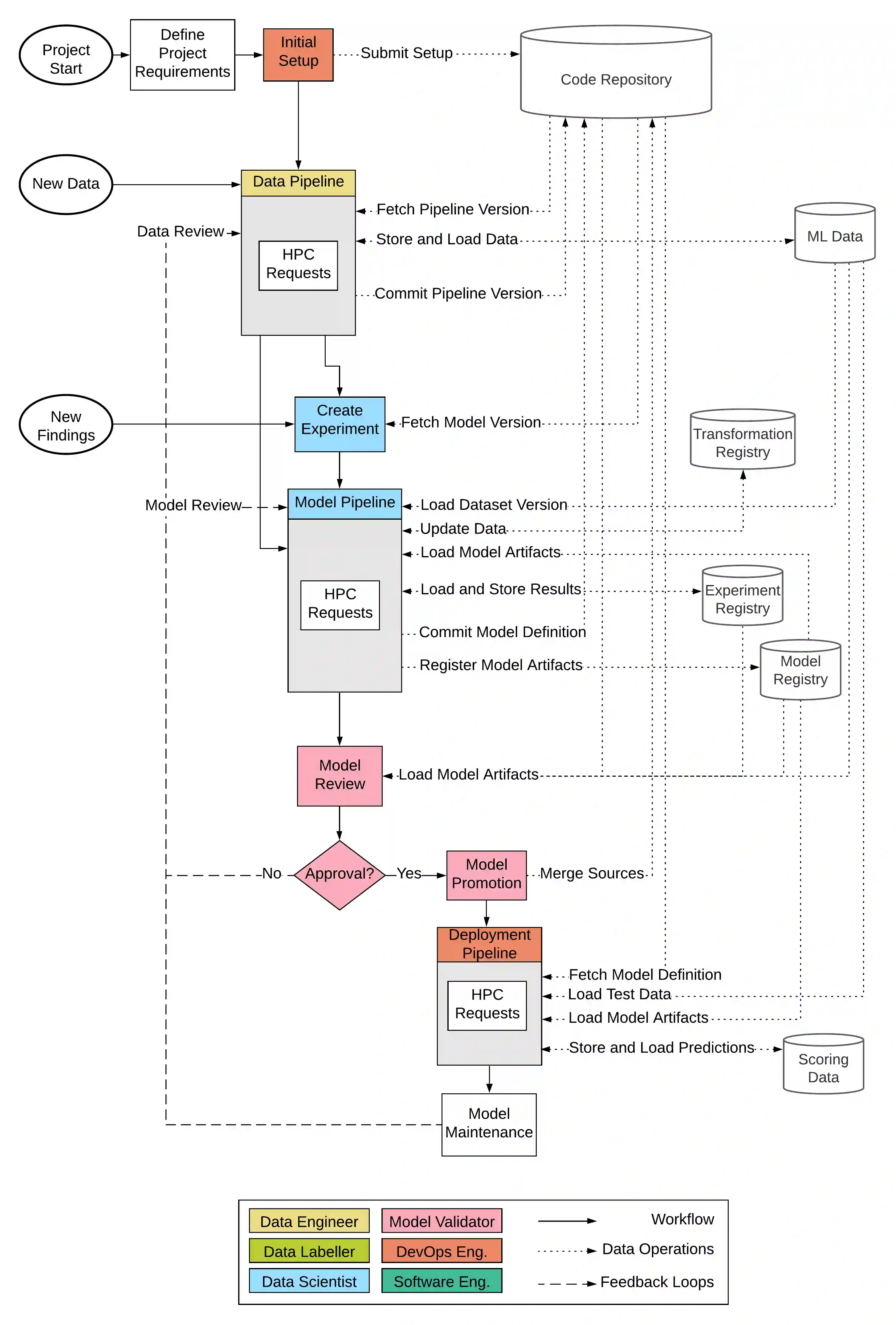
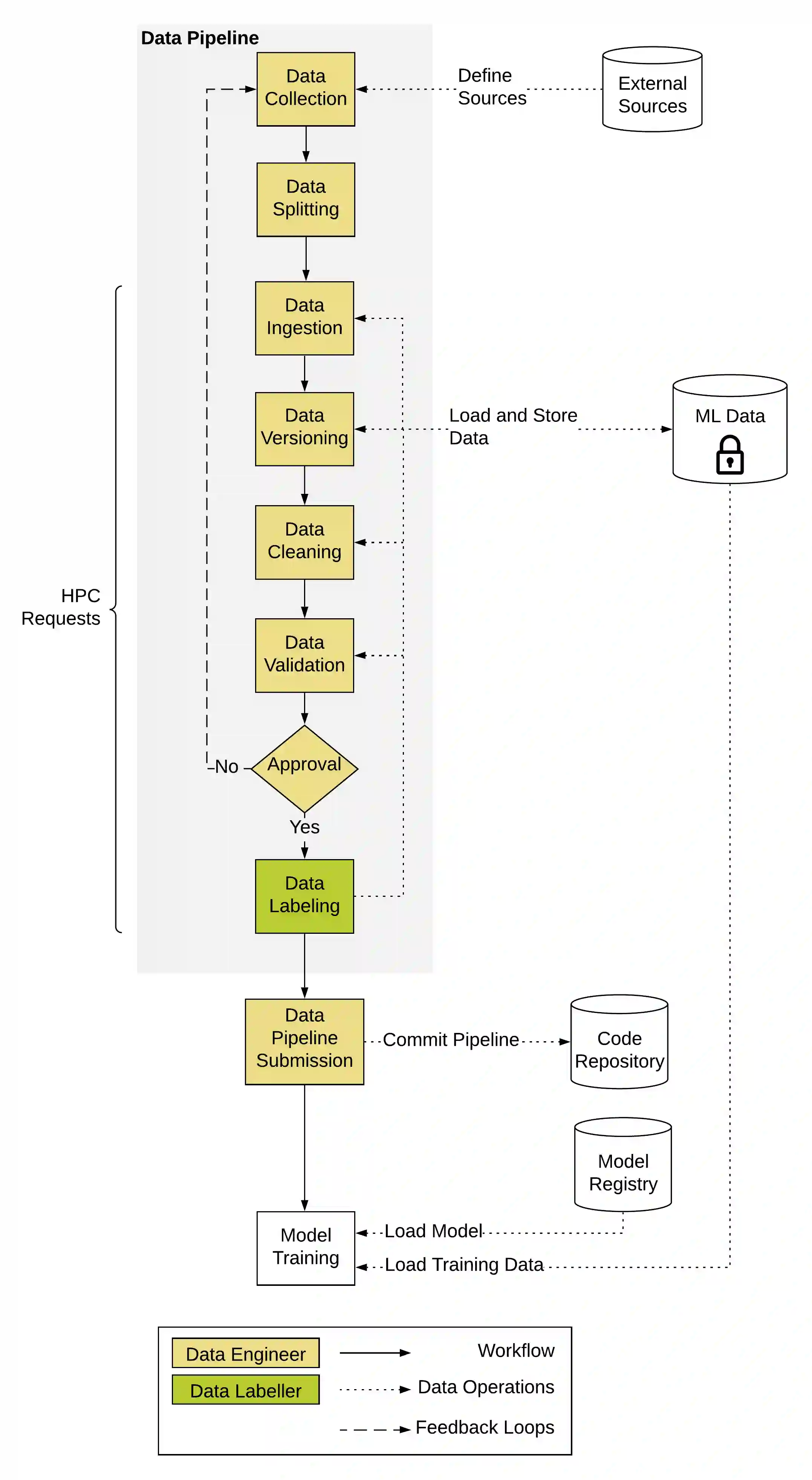
Researchers have been highly active to investigate the classical machine learning workflow and integrate best practices from the software engineering lifecycle. However, deep learning exhibits deviations that are not yet covered in this conceptual development process. This includes the requirement of dedicated hardware, dispensable feature engineering, extensive hyperparameter optimization, large-scale data management, and model compression to reduce size and inference latency. Individual problems of deep learning are under thorough examination, and numerous concepts and implementations have gained traction. Unfortunately, the complete end-to-end development process still remains unspecified. In this paper, we define a detailed deep learning workflow that incorporates the aforementioned characteristics on the baseline of the classical machine learning workflow. We further transferred the conceptual idea into practice by building a prototypic deep learning system using some of the latest technologies on the market. To examine the feasibility of the workflow, two use cases are applied to the prototype.
翻译:研究人员一直非常积极地调查古典机器学习工作流程,并整合软件工程生命周期的最佳做法;然而,深层学习显示在概念开发过程中尚未涵盖的偏差,包括需要专用硬件、可忽略的特征工程、广泛的超光度优化、大规模数据管理和模型压缩以减少规模和推理延度;正在对深层学习的个别问题进行彻底审查,许多概念和执行过程获得了牵引;不幸的是,完整的端对端开发过程仍未明确。在本文件中,我们界定了详细的深层学习工作流程,其中纳入了古典机器学习工作流程基线上的上述特征。我们进一步将概念概念转化为实践,方法是利用市场上的一些最新技术建立一个原型深层学习系统。为了研究工作流程的可行性,对原型应用了两个案例。