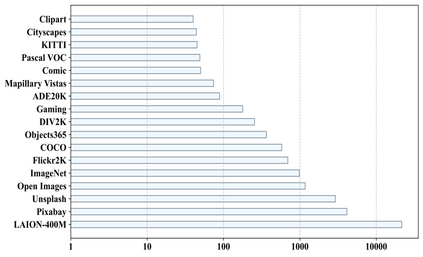
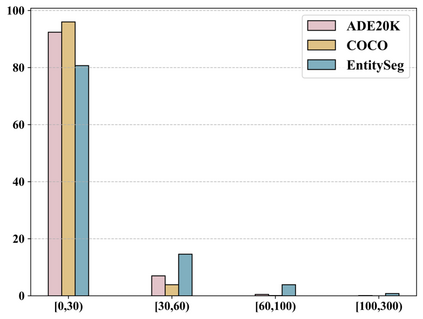
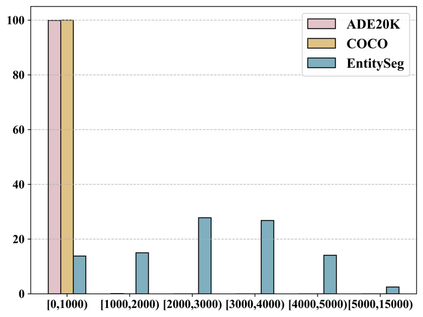
In dense image segmentation tasks (e.g., semantic, panoptic), existing methods can hardly generalize well to unseen image domains, predefined classes, and image resolution & quality variations. Motivated by these observations, we construct a large-scale entity segmentation dataset to explore fine-grained entity segmentation, with a strong focus on open-world and high-quality dense segmentation. The dataset contains images spanning diverse image domains and resolutions, along with high-quality mask annotations for training and testing. Given the high-quality and -resolution nature of the dataset, we propose CropFormer for high-quality segmentation, which can improve mask prediction using high-res image crops that provide more fine-grained image details than the full image. CropFormer is the first query-based Transformer architecture that can effectively ensemble mask predictions from multiple image crops, by learning queries that can associate the same entities across the full image and its crop. With CropFormer, we achieve a significant AP gain of $1.9$ on the challenging fine-grained entity segmentation task. The dataset and code will be released at http://luqi.info/entityv2.github.io/.
翻译:在浓密的图像分割任务(例如,语义、泛光)中,现有方法几乎无法向看不见的图像域、预定义的分类、图像分辨率和质量变异等全面概括现有方法。根据这些观察,我们建造了一个大型实体分解数据集,以探索细微区分的实体分解,其中以开放世界和高质量的密集分解为主要重点。该数据集包含涵盖不同图像域和分辨率的图像,以及高质量的培训和测试掩码说明。鉴于数据集的高质量和分辨率性质,我们提议高品质分解的CropFormer,这可以用高档图像作物改进遮罩预测,而高档图像作物提供比整幅图像更精细的图像细节。CropFormer是第一个基于查询的变异器结构,它能够有效地将多个图像作物的预测叠加在一起。通过CropFormer,我们在具有挑战性的精度实体分解任务上取得了相当1.9美元的AP收益。数据设置和代码将在 http://luivo2上发布。数据设置和代码。