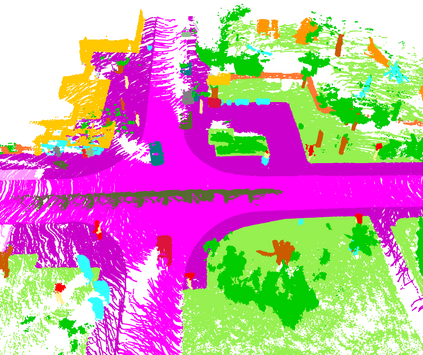
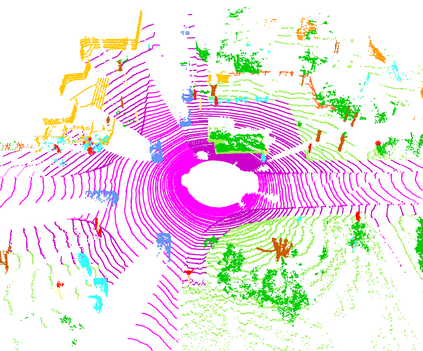
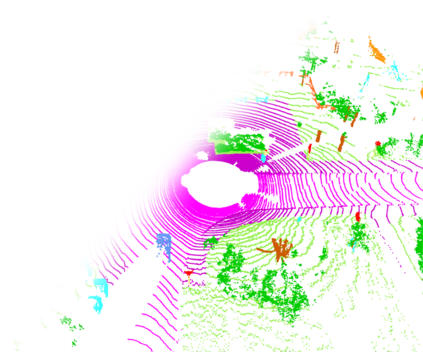
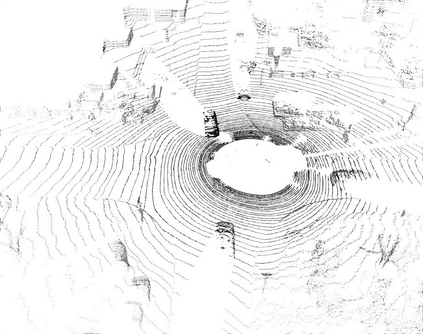
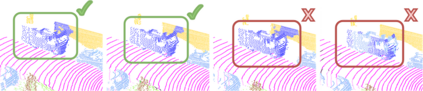
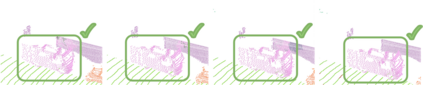
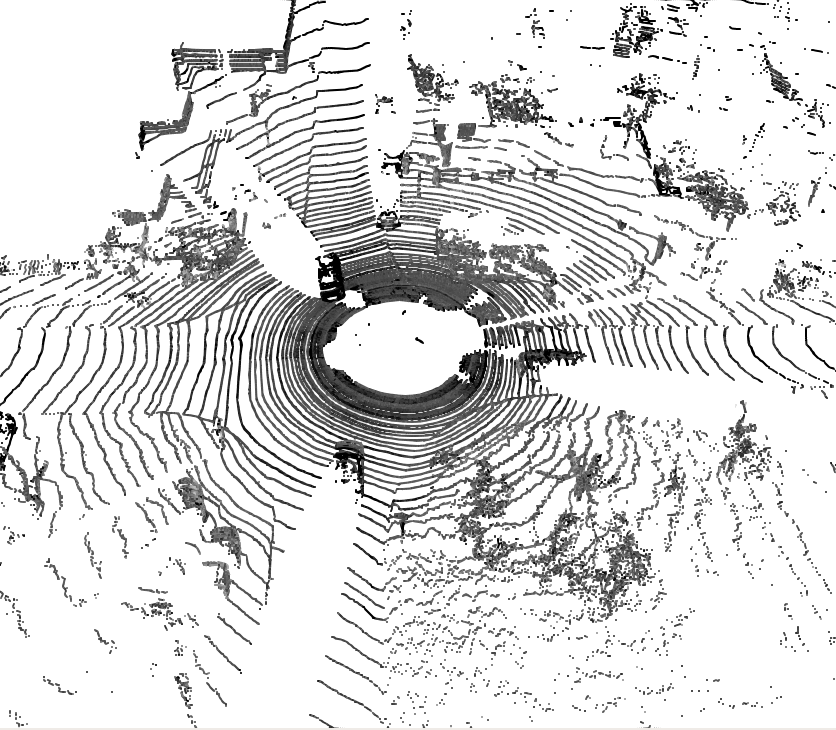
Temporal semantic scene understanding is critical for self-driving cars or robots operating in dynamic environments. In this paper, we propose 4D panoptic LiDAR segmentation to assign a semantic class and a temporally-consistent instance ID to a sequence of 3D points. To this end, we present an approach and a point-centric evaluation metric. Our approach determines a semantic class for every point while modeling object instances as probability distributions in the 4D spatio-temporal domain. We process multiple point clouds in parallel and resolve point-to-instance associations, effectively alleviating the need for explicit temporal data association. Inspired by recent advances in benchmarking of multi-object tracking, we propose to adopt a new evaluation metric that separates the semantic and point-to-instance association aspects of the task. With this work, we aim at paving the road for future developments of temporal LiDAR panoptic perception.
翻译:时间语义场景理解对于在动态环境中运行的汽车或机器人自行驾驶汽车或机器人至关重要。 在本文中, 我们提议四维全光 LiDAR 分割法, 将语义类和时间一致的例代号指定为3D点的序列。 为此, 我们提出一个方法和一个点心评价度度。 我们的方法为每个点确定一个语义类, 同时将物体实例建模作为4D spotio- 时空域的概率分布。 我们同时处理多点云, 解决点对点关联, 有效减轻对明确时间数据关联的需求。 我们建议, 在多点跟踪基准的最近进展下, 采用一个新的评估指标, 将任务的语义和点对点关联方面区分开来。 通过这项工作, 我们的目标是为LIDAR 光学感知的未来发展铺路。