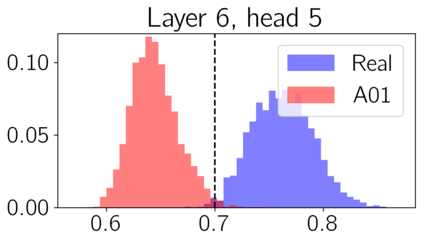
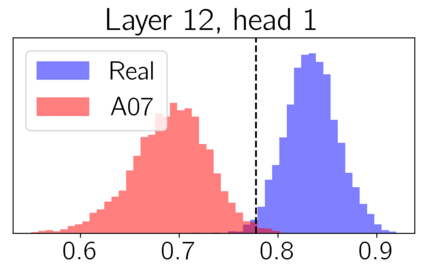
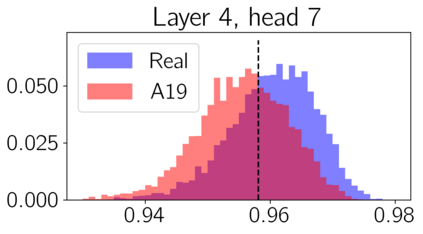
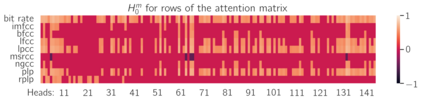
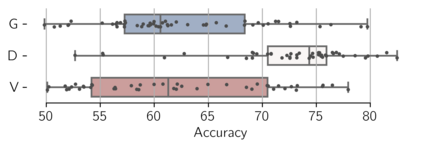
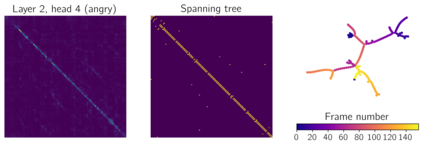
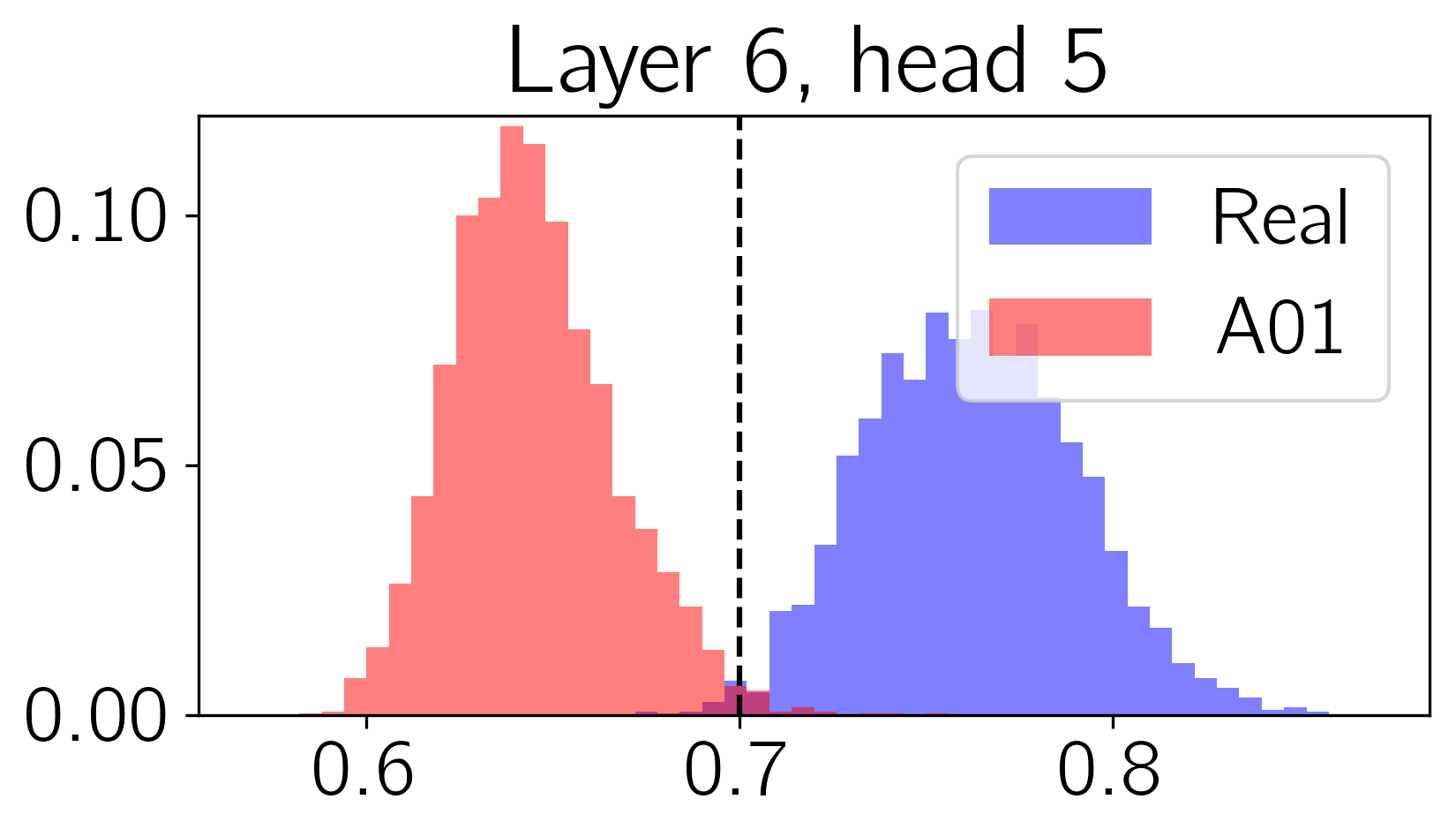
We apply topological data analysis (TDA) to speech classification problems and to the introspection of a pretrained speech model, HuBERT. To this end, we introduce a number of topological and algebraic features derived from Transformer attention maps and embeddings. We show that a simple linear classifier built on top of such features outperforms a fine-tuned classification head. In particular, we achieve an improvement of about $9\%$ accuracy and $5\%$ ERR on four common datasets; on CREMA-D, the proposed feature set reaches a new state of the art performance with accuracy $80.155$. We also show that topological features are able to reveal functional roles of speech Transformer heads; e.g., we find the heads capable to distinguish between pairs of sample sources (natural/synthetic) or voices without any downstream fine-tuning. Our results demonstrate that TDA is a promising new approach for speech analysis, especially for tasks that require structural prediction.
翻译:我们用地形数据分析(TDA)来分析语言分类问题和对预先训练的语音模型HuBERT进行反省。为此,我们引入了来自变换器注意力地图和嵌入器的一些地形学和代数特征。我们发现,在这类特征上面建起的一个简单的线性分类器,优于一个微调的分类头。特别是,我们在四个通用数据集上提高了大约9美元准确度和5美元ERR;在CREMA-D上,拟议的功能组达到艺术性能的新状态,准确度为80.155美元。我们还显示,地形特征能够揭示变换器头部的功能作用;例如,我们发现能够区分抽样来源(自然/合成)或没有下游微调的声音的两对头。我们的结果显示,TDA是一种有希望的新语言分析方法,特别是在需要结构性预测的任务上。