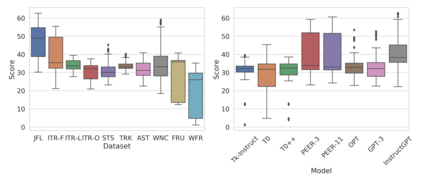
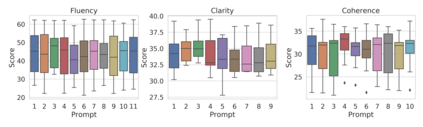
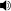Evaluation of text generation to date has primarily focused on content created sequentially, rather than improvements on a piece of text. Writing, however, is naturally an iterative and incremental process that requires expertise in different modular skills such as fixing outdated information or making the style more consistent. Even so, comprehensive evaluation of a model's capacity to perform these skills and the ability to edit remains sparse. This work presents EditEval: An instruction-based, benchmark and evaluation suite that leverages high-quality existing and new datasets for automatic evaluation of editing capabilities such as making text more cohesive and paraphrasing. We evaluate several pre-trained models, which shows that InstructGPT and PEER perform the best, but that most baselines fall below the supervised SOTA, particularly when neutralizing and updating information. Our analysis also shows that commonly used metrics for editing tasks do not always correlate well, and that optimization for prompts with the highest performance does not necessarily entail the strongest robustness to different models. Through the release of this benchmark and a publicly available leaderboard challenge, we hope to unlock future research in developing models capable of iterative and more controllable editing.
翻译:迄今为止,对生成文本的评价主要侧重于按顺序创建的内容,而不是对文本的改进。然而,写作自然是一个迭代和渐进的过程,需要不同模块技能的专门知识,例如修复过时的信息或使风格更加一致。即使如此,对模型进行这些技能的运用能力和编辑能力的全面评价仍然很少。这项工作提出了《EditEval:一个基于教学、基准和评价的套件》,它利用高质量的现有和新的数据集对编辑能力进行自动评价,例如使文本更具凝聚力和参数化。我们评价了若干预先培训的模型,它表明教官GPT和PEER表现最佳,但大多数基线都低于监督的SOTA,特别是在中和增订信息时。我们的分析还表明,编辑任务通常使用的标准并不总是很好地相互联系,而且对最高性能的及时性进行优化并不一定意味着对不同模型的优化。通过发布这一基准和公开使用的领导板的挑战,我们希望在开发能够进行迭接和更加可控制的编辑的模型方面释放未来的研究。