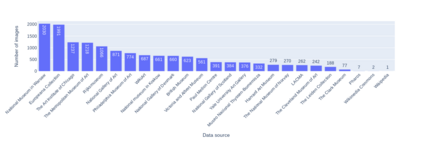
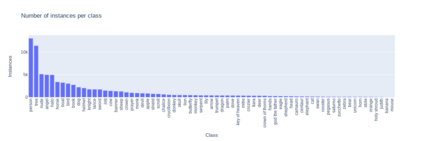
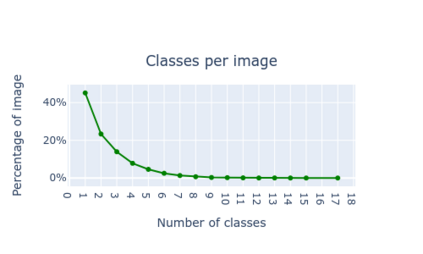
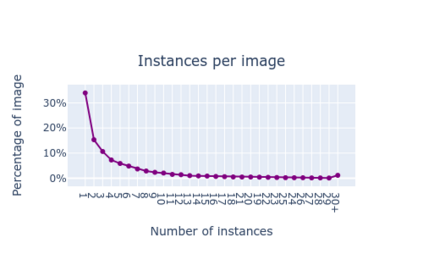
Large datasets that were made publicly available to the research community over the last 20 years have been a key enabling factor for the advances in deep learning algorithms for NLP or computer vision. These datasets are generally pairs of aligned image / manually annotated metadata, where images are photographs of everyday life. Scholarly and historical content, on the other hand, treat subjects that are not necessarily popular to a general audience, they may not always contain a large number of data points, and new data may be difficult or impossible to collect. Some exceptions do exist, for instance, scientific or health data, but this is not the case for cultural heritage (CH). The poor performance of the best models in computer vision - when tested over artworks - coupled with the lack of extensively annotated datasets for CH, and the fact that artwork images depict objects and actions not captured by photographs, indicate that a CH-specific dataset would be highly valuable for this community. We propose DEArt, at this point primarily an object detection and pose classification dataset meant to be a reference for paintings between the XIIth and the XVIIIth centuries. It contains more than 15000 images, about 80% non-iconic, aligned with manual annotations for the bounding boxes identifying all instances of 69 classes as well as 12 possible poses for boxes identifying human-like objects. Of these, more than 50 classes are CH-specific and thus do not appear in other datasets; these reflect imaginary beings, symbolic entities and other categories related to art. Additionally, existing datasets do not include pose annotations. Our results show that object detectors for the cultural heritage domain can achieve a level of precision comparable to state-of-art models for generic images via transfer learning.
翻译:过去20年来向研究界公开提供的大型数据集,在过去20年中,对于NLP或计算机视觉的深层次学习算法的进步来说,是一个关键的有利因素。这些数据集通常是一对对对齐图像/手动附加说明的元数据,在这些元数据中,图像是日常生活的照片。另一方面,学术和历史内容处理不一定对一般受众开放的科目,它们不一定包含大量数据点,新的数据可能很难或不可能收集。有些例外确实存在,例如科学或健康数据,但文化遗产(CH)却不是这样。计算机视觉中最佳的通用精确模型表现不佳,在经过艺术作品测试时,加上缺少广泛的附加说明的数据集,以及艺术图像描述非照片拍摄对象和行动的事实,表明对这个群体来说,CH专用的数据集可能并不十分宝贵。我们建议DEArt在这一点上首先进行物体探测,并设置分类数据集,目的是在第十二世纪和十八世纪之间的绘画中作为参考,但这不是文化遗产(CH) 。在计算机视野中, 最佳的通用模型的模型表现不甚甚甚佳, 将18000 的模型中, 将显示我们现有的18个日历中的其他图表显示为18级。