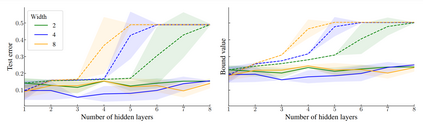
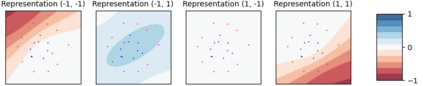
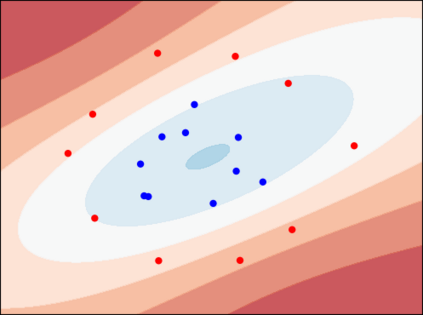
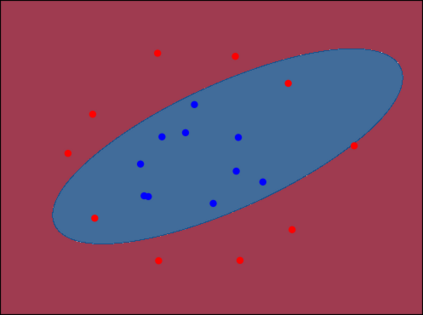
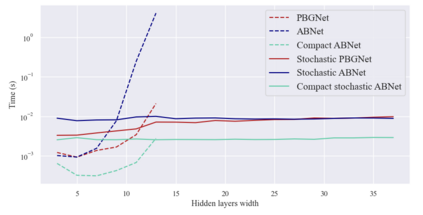
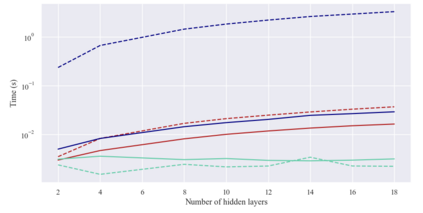
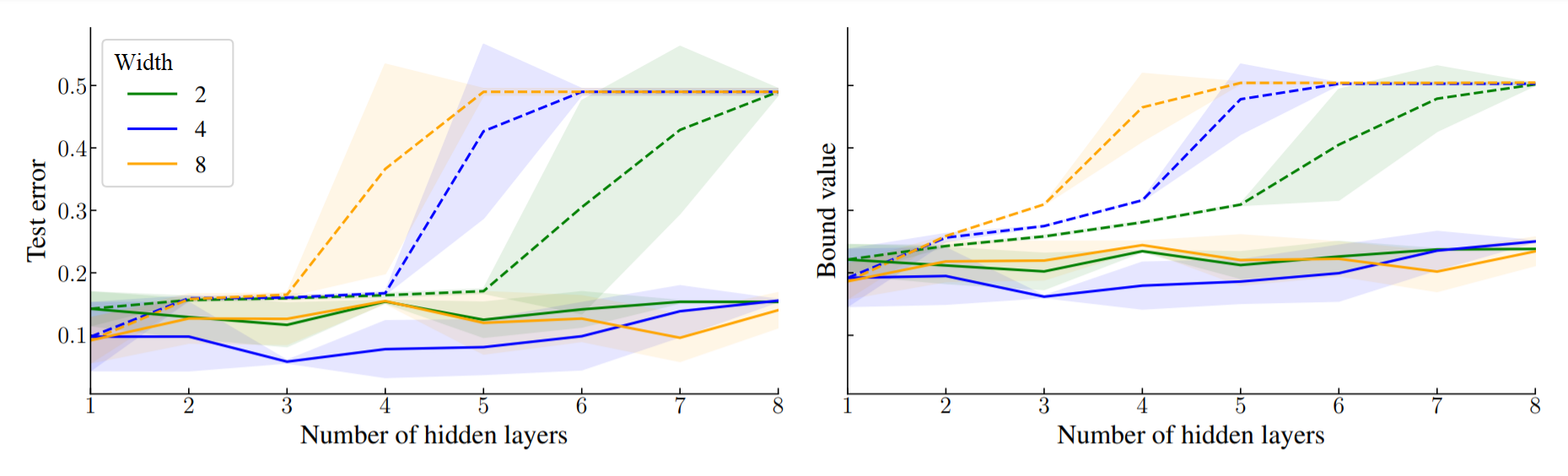
Considering a probability distribution over parameters is known as an efficient strategy to learn a neural network with non-differentiable activation functions. We study the expectation of a probabilistic neural network as a predictor by itself, focusing on the aggregation of binary activated neural networks with normal distributions over real-valued weights. Our work leverages a recent analysis derived from the PAC-Bayesian framework that derives tight generalization bounds and learning procedures for the expected output value of such an aggregation, which is given by an analytical expression. While the combinatorial nature of the latter has been circumvented by approximations in previous works, we show that the exact computation remains tractable for deep but narrow neural networks, thanks to a dynamic programming approach. This leads us to a peculiar bound minimization learning algorithm for binary activated neural networks, where the forward pass propagates probabilities over representations instead of activation values. A stochastic counterpart of this new neural networks training scheme that scales to wider architectures is proposed.
翻译:将参数的概率分布考虑在内被认为是一种有效的战略,可以学习具有不可区别的激活功能的神经网络。我们研究对概率神经网络本身作为预测器的期望,侧重于将二进制活性神经网络与正常分布于实际价值重量之上的正常神经网络聚合在一起。我们的工作利用了从PAC-Bayesian框架得出的最新分析,该分析为这种聚合的预期产出值提供了紧凑的概括性界限和学习程序,该分析表达方式给出了这种集合的预期产出值。虽然后者的组合性质已经被先前工作中的近似所绕过,但我们显示精确的计算仍然可以用于深而狭窄的神经网络,这得益于动态的编程方法。这导致我们形成了一种对二进制活性神经网络的特殊的最小化学习算法,在这种网络中,前端传传传传传递的比表示值的概率大于激活值的概率。提出了这个新的神经网络培训计划的一个随机对应方法,该方法将规模扩大到更广泛的结构。