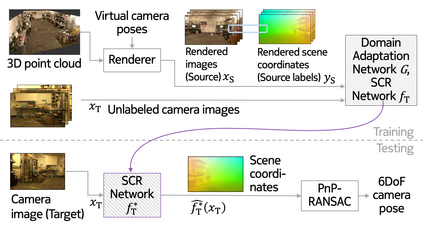
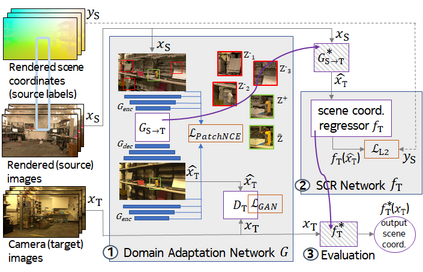
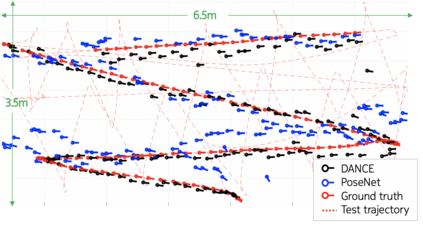
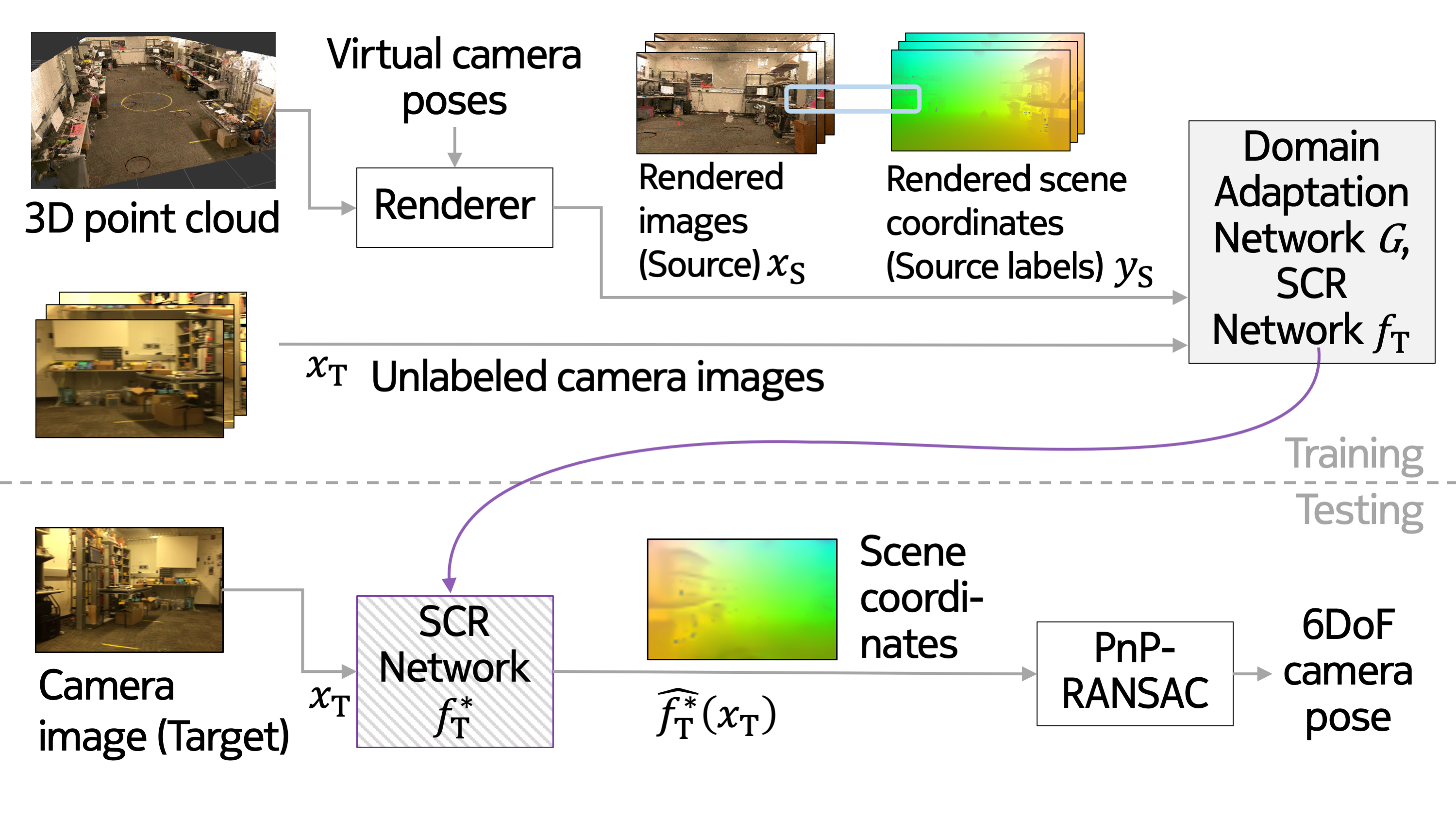
One of the key criticisms of deep learning is that large amounts of expensive and difficult-to-acquire training data are required in order to train models with high performance and good generalization capabilities. Focusing on the task of monocular camera pose estimation via scene coordinate regression (SCR), we describe a novel method, Domain Adaptation of Networks for Camera pose Estimation (DANCE), which enables the training of models without access to any labels on the target task. DANCE requires unlabeled images (without known poses, ordering, or scene coordinate labels) and a 3D representation of the space (e.g., a scanned point cloud), both of which can be captured with minimal effort using off-the-shelf commodity hardware. DANCE renders labeled synthetic images from the 3D model, and bridges the inevitable domain gap between synthetic and real images by applying unsupervised image-level domain adaptation techniques (unpaired image-to-image translation). When tested on real images, the SCR model trained with DANCE achieved comparable performance to its fully supervised counterpart (in both cases using PnP-RANSAC for final pose estimation) at a fraction of the cost. Our code and dataset are available at https://github.com/JackLangerman/dance
翻译:深层学习的关键批评之一是,需要大量昂贵和难以获得的培训数据,才能对具有高性能和良好一般化能力的模型进行培训。侧重于单镜相机的任务,通过现场协调回归(SCR)进行估计,我们描述一种新颖的方法,即“相机网络的域改造”带来动动画(Dance),使模型培训无法接触到目标任务的任何标签。 舞蹈需要大量没有标签的图像(没有已知的配置、订购或现场协调标签)和3D的空间代表(例如扫描点云),两者都可以以极少的努力利用现成的商品硬件来捕捉。 丹斯将3D模型的合成图像贴上标签,并通过应用不受监督的图像级别适应技术(未受监督的图像到图像翻译)来弥合合成图像与真实图像之间不可避免的领域差距。 在实际图像测试时,经过DCREC培训的SCR模型取得了与其完全监督的对应方(在使用P-NSiabrAC的两种情况下,使用P-NSabrm/L的软件,可用于最终估算)。