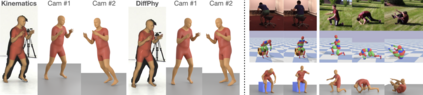
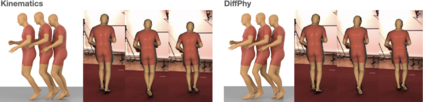
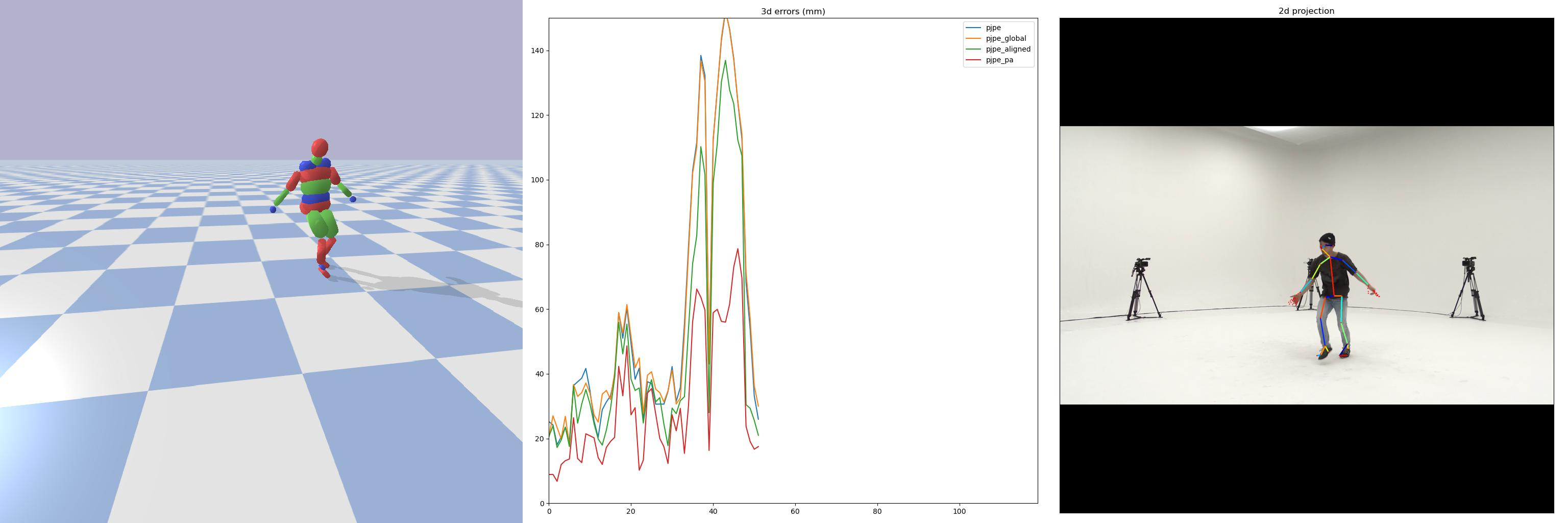
We introduce DiffPhy, a differentiable physics-based model for articulated 3d human motion reconstruction from video. Applications of physics-based reasoning in human motion analysis have so far been limited, both by the complexity of constructing adequate physical models of articulated human motion, and by the formidable challenges of performing stable and efficient inference with physics in the loop. We jointly address such modeling and inference challenges by proposing an approach that combines a physically plausible body representation with anatomical joint limits, a differentiable physics simulator, and optimization techniques that ensure good performance and robustness to suboptimal local optima. In contrast to several recent methods, our approach readily supports full-body contact including interactions with objects in the scene. Most importantly, our model connects end-to-end with images, thus supporting direct gradient-based physics optimization by means of image-based loss functions. We validate the model by demonstrating that it can accurately reconstruct physically plausible 3d human motion from monocular video, both on public benchmarks with available 3d ground-truth, and on videos from the internet.
翻译:我们引入了DiffPhy, 这是一种以物理为基础的不同模型,用于用视频对三部人类运动进行分解重建。在人类运动分析中应用基于物理的推理到目前为止受到了限制,其原因有二:一方面是设计出适当的人运动物理模型的复杂性,另一方面是进行与物理循环的稳定和有效推断的巨大挑战。我们共同应对这种模型和推论方面的挑战,方法是提出一种方法,将物理上可行的身体代表与解剖联合限制、不同的物理模拟器和优化技术结合起来,确保良好的性能和稳健性,以至局部的不优化。与最近的一些方法不同,我们的方法是随时支持全体接触,包括与现场物体的互动。最重要的是,我们的模型将终端到终端与图像连接起来,从而通过图像损失功能支持直接的基于梯度的物理优化。我们验证模型的方法是,它能够精确地从单色视频中重建出物理上可信的三部人类运动,既以公共基准为基础,有3个地面图理,也从互联网视频上精确地重建。