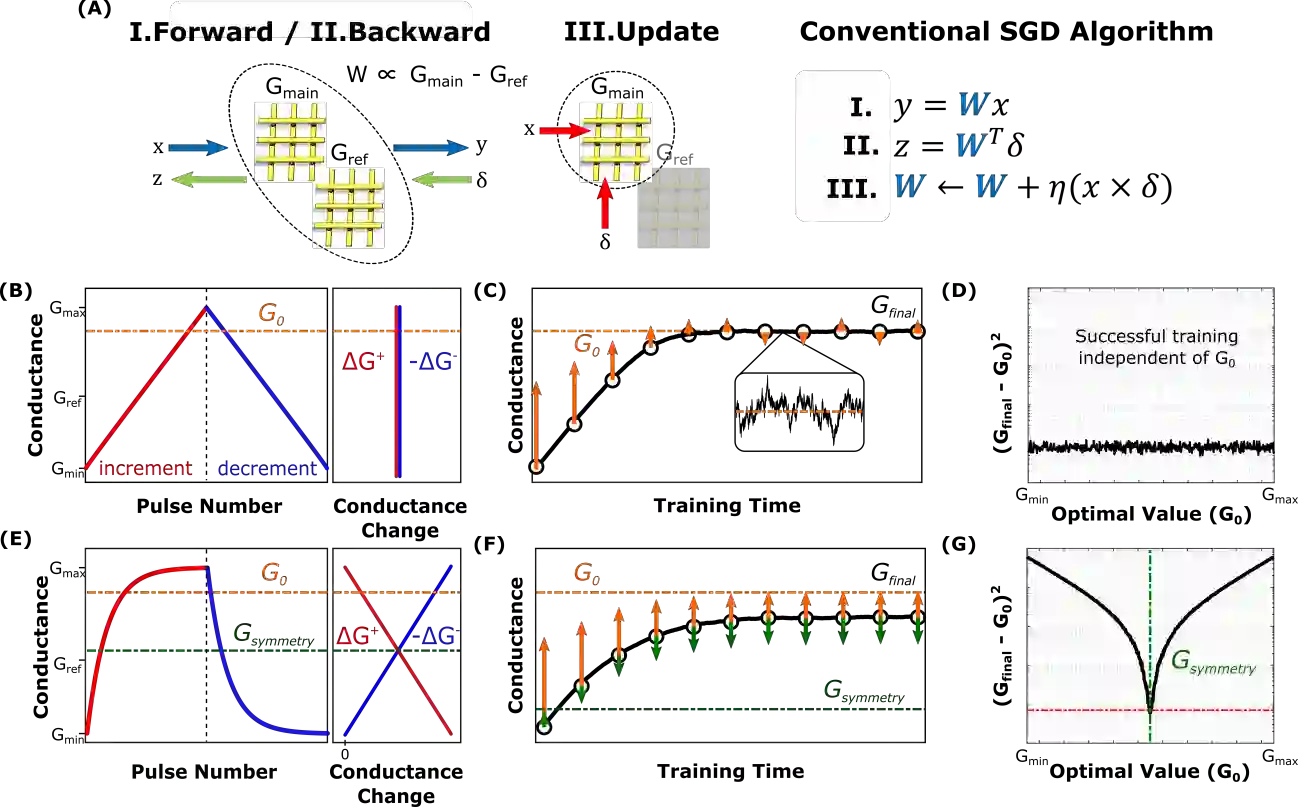
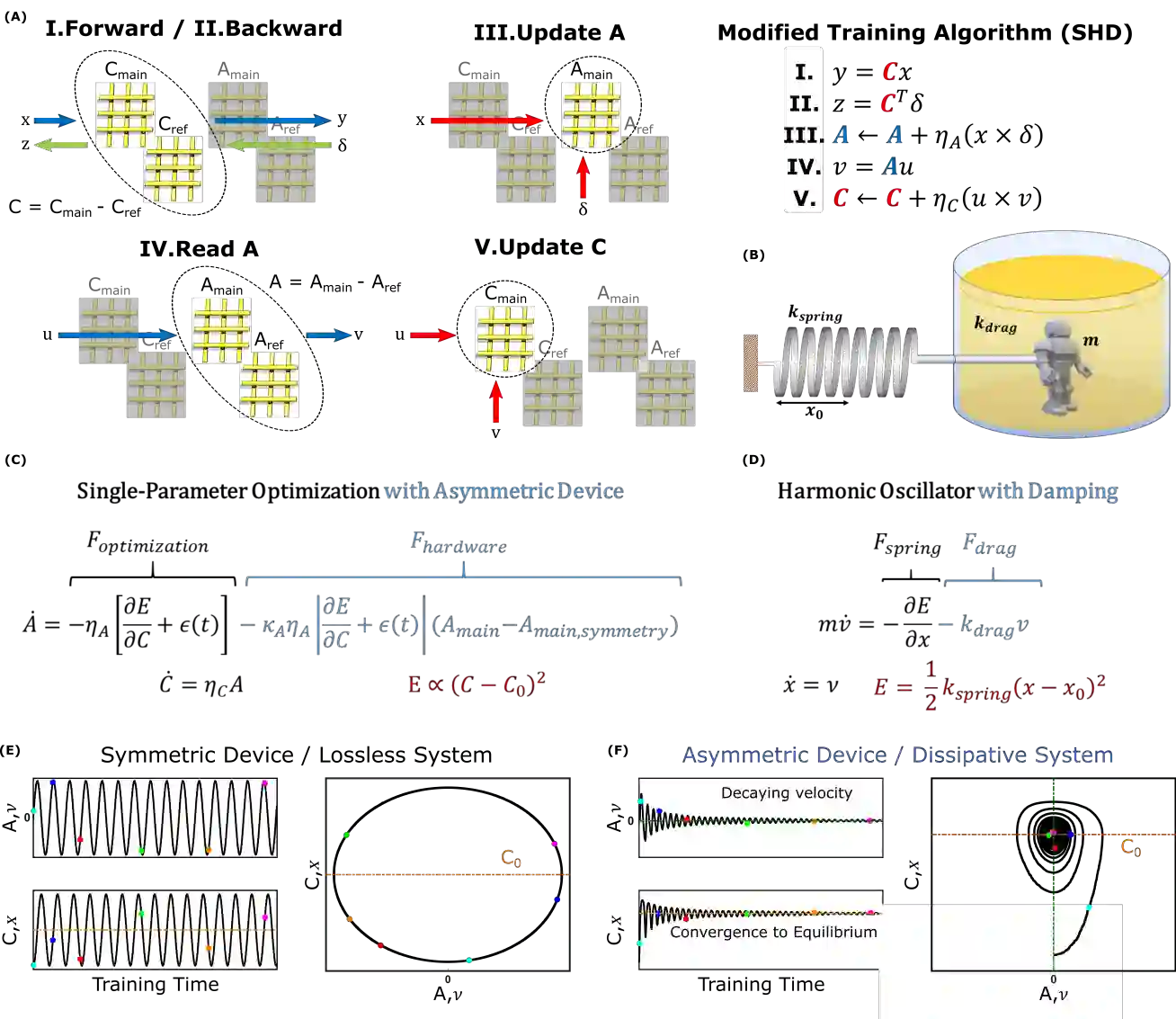
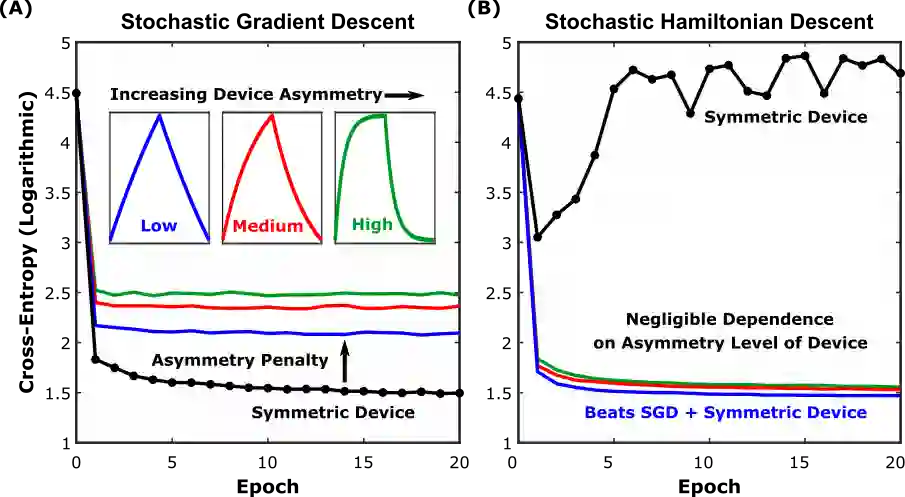
Analog crossbar arrays comprising programmable nonvolatile resistors are under intense investigation for acceleration of deep neural network training. However, the ubiquitous asymmetric conductance modulation of practical resistive devices critically degrades the classification performance of networks trained with conventional algorithms. Here, we describe and experimentally demonstrate an alternative fully-parallel training algorithm: Stochastic Hamiltonian Descent. Instead of conventionally tuning weights in the direction of the error function gradient, this method programs the network parameters to successfully minimize the total energy (Hamiltonian) of the system that incorporates the effects of device asymmetry. We provide critical intuition on why device asymmetry is fundamentally incompatible with conventional training algorithms and how the new approach exploits it as a useful feature instead. Our technique enables immediate realization of analog deep learning accelerators based on readily available device technologies.
翻译:由可编程的非挥发性抵抗器组成的模拟横条阵列正在深入调查中,以加速深神经网络培训。然而,对实际抗力装置进行无处不在的不对称行为调节,严重降低了经过常规算法培训的网络的分类性能。在这里,我们描述并实验性地展示了一种完全平行培训的替代算法:斯托切斯·汉密尔顿派后裔。这种方法不是常规地调整错误函数梯度方向的重量,而是将包含装置不对称效应的系统的总能量(Hamiltonian)控制在网络参数上,以成功最小化。我们提供了关键直觉,说明为什么设备不对称从根本上与常规培训算法不兼容,以及新方法如何将它作为一种有用的特性加以利用。我们的技术使得能够立即实现基于现成的装置技术的模拟深度学习加速器。