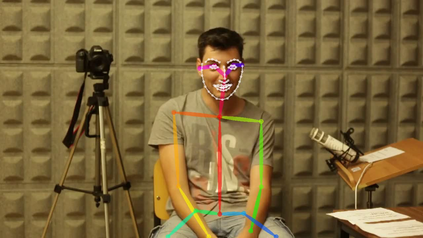
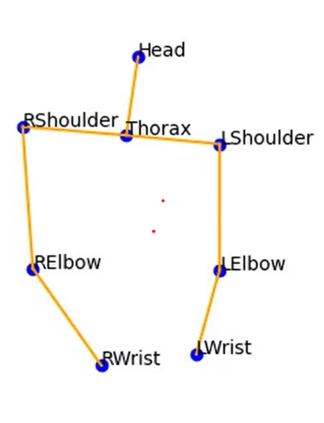
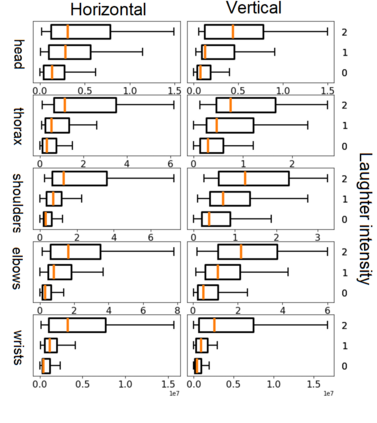
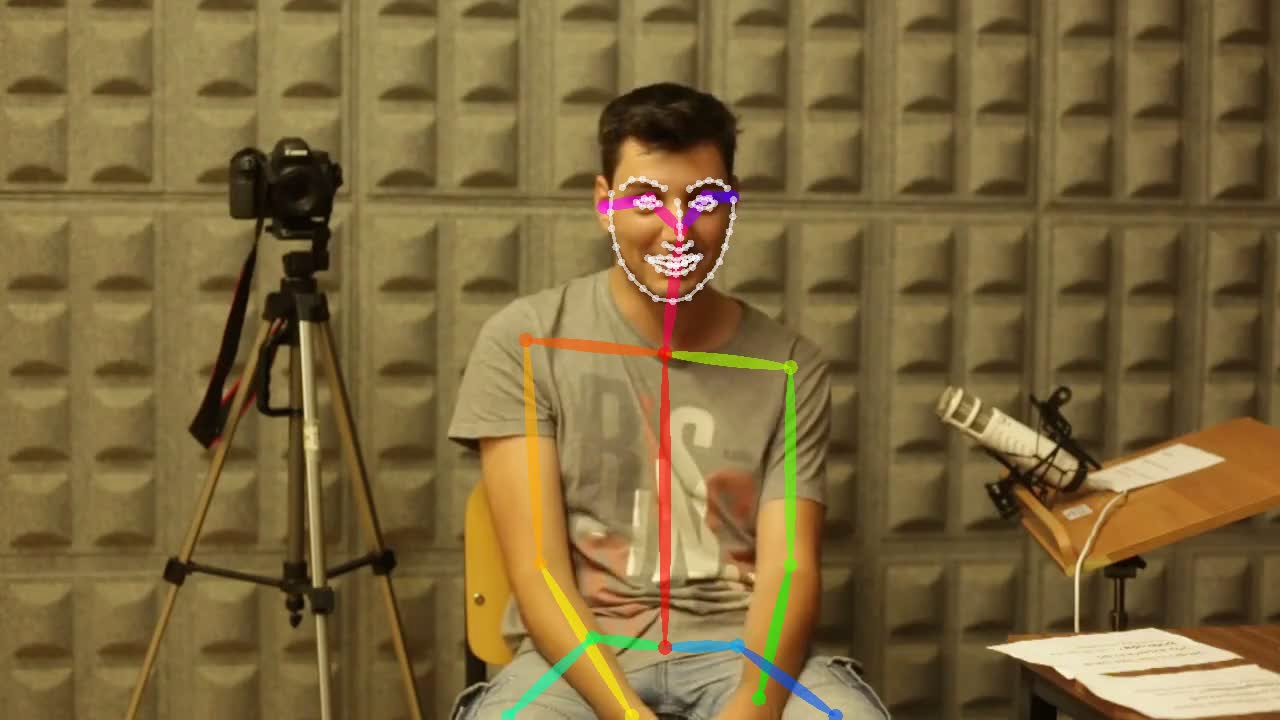
The development of virtual agents has enabled human-avatar interactions to become increasingly rich and varied. Moreover, an expressive virtual agent i.e. that mimics the natural expression of emotions, enhances social interaction between a user (human) and an agent (intelligent machine). The set of non-verbal behaviors of a virtual character is, therefore, an important component in the context of human-machine interaction. Laughter is not just an audio signal, but an intrinsic relationship of multimodal non-verbal communication, in addition to audio, it includes facial expressions and body movements. Motion analysis often relies on a relevant motion capture dataset, but the main issue is that the acquisition of such a dataset is expensive and time-consuming. This work studies the relationship between laughter and body movements in dyadic conversations. The body movements were extracted from videos using deep learning based pose estimator model. We found that, in the explored NDC-ME dataset, a single statistical feature (i.e, the maximum value, or the maximum of Fourier transform) of a joint movement weakly correlates with laughter intensity by 30%. However, we did not find a direct correlation between audio features and body movements. We discuss about the challenges to use such dataset for the audio-driven co-laughter motion synthesis task.
翻译:虚拟代理器的发展使人与行人的互动变得日益丰富和多样化。此外,一个表现式虚拟代理器,即模仿情感的自然表达,加强用户(人)和代理(智能机器)之间的社会互动。因此,一套虚拟字符的非口头行为是人体与机器互动的一个重要部分。笑笑不仅仅是一个音频信号,而且是多式联运非口头通信的内在关系,除了音频外,它还包括面部表达和身体运动。运动分析往往依赖于相关的运动捕获数据集,但主要问题是获取这样一个数据集既昂贵又耗时。这项工作研究了在dyadic交谈中的笑声与身体运动之间的关系。身体运动是利用基于深学习的姿势估计模型从视频中提取的。我们发现,在所探索的NDC-ME数据集中,一个单一的统计特征(即面部的最大价值或四面体变的最大值),一个与30 % 的笑强度相关联的动态。但是,我们没有在磁力驱动的图像中找到一个直接的链接。