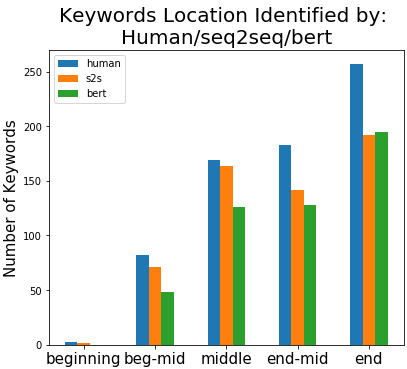
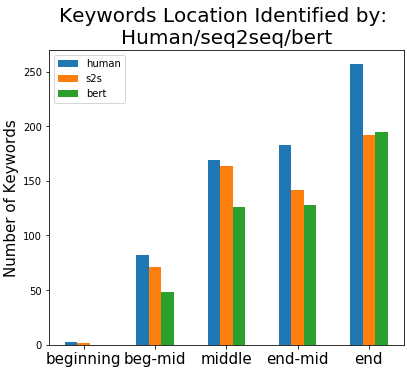
Recent research has shown that mixed-initiative conversational search, based on the interaction between users and computers to clarify and improve a query, provides enormous advantages. Nonetheless, incorporating additional information provided by the user from the conversation poses some challenges. In fact, further interactions could confuse the system as a user might use words irrelevant to the information need but crucial for correct sentence construction in the context of multi-turn conversations. To this aim, in this paper, we have collected two conversational keyword extraction datasets and propose an end-to-end document retrieval pipeline incorporating them. Furthermore, we study the performance of two neural keyword extraction models, namely, BERT and sequence to sequence, in terms of extraction accuracy and human annotation. Finally, we study the effect of keyword extraction on the end-to-end neural IR performance and show that our approach beats state-of-the-art IR models. We make the two datasets publicly available to foster research in this area.
翻译:最近的研究显示,基于用户和计算机之间的互动,以澄清和改进查询,进行混合性对话搜索,具有巨大的优势;然而,将用户从谈话中提供的额外信息纳入其中,带来了一些挑战;事实上,进一步的互动可能会使系统混淆,因为用户可能会使用与信息需要无关但对于在多转对话中正确构建句子至关重要的词句。为此,我们在本文件中收集了两个对话关键词提取数据集,并提议了一个包含这些数据的端到端文件检索管道。此外,我们还研究了两个神经关键词提取模型的性能,即BERT和顺序序列,即提取精度和人文说明。最后,我们研究了关键词提取对终端到终端神经仪性能的影响,并展示了我们的方法优于最先进的IR模型。我们公开了这两个数据集,以促进这一领域的研究。