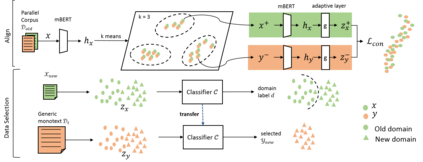
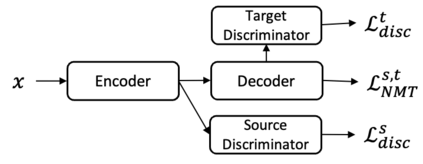
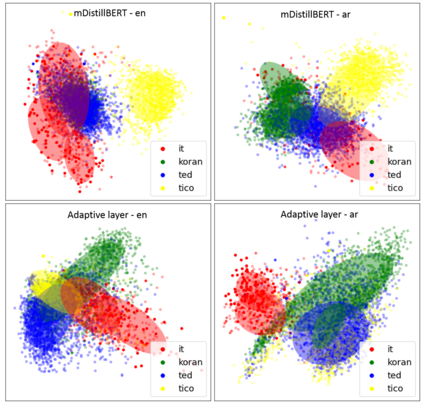
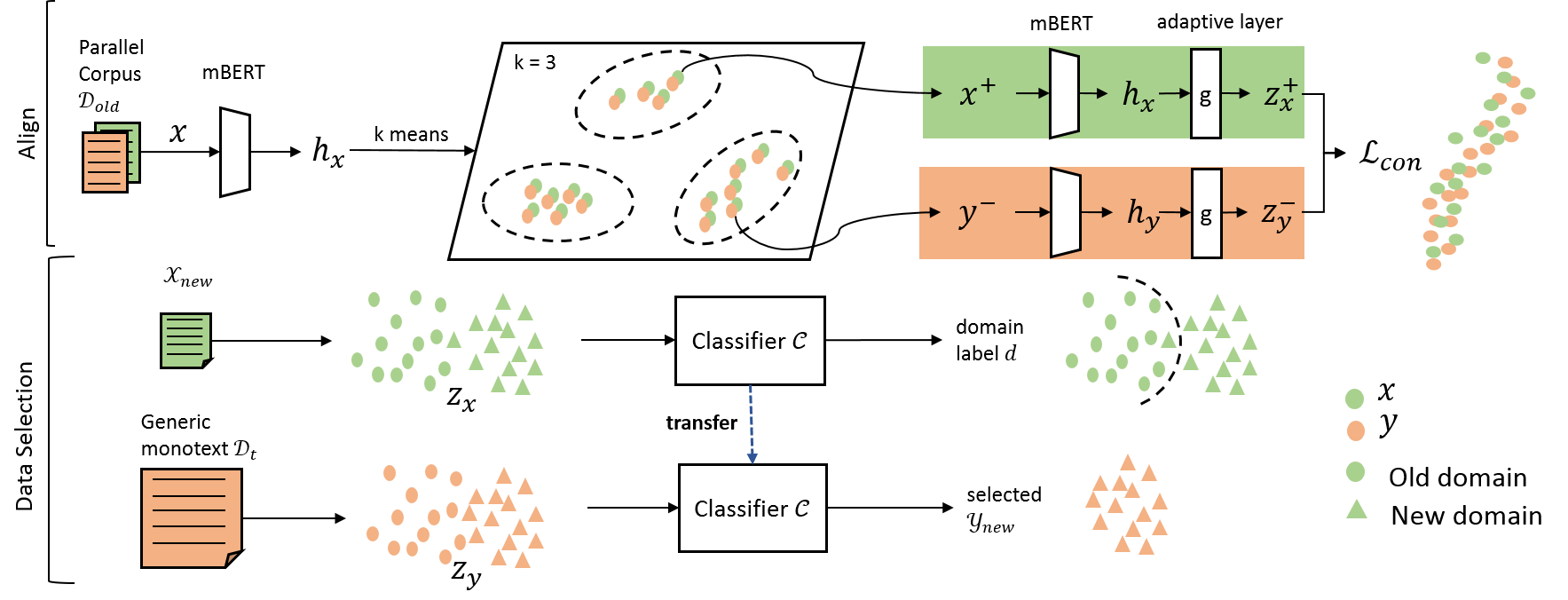
This paper considers the unsupervised domain adaptation problem for neural machine translation (NMT), where we assume the access to only monolingual text in either the source or target language in the new domain. We propose a cross-lingual data selection method to extract in-domain sentences in the missing language side from a large generic monolingual corpus. Our proposed method trains an adaptive layer on top of multilingual BERT by contrastive learning to align the representation between the source and target language. This then enables the transferability of the domain classifier between the languages in a zero-shot manner. Once the in-domain data is detected by the classifier, the NMT model is then adapted to the new domain by jointly learning translation and domain discrimination tasks. We evaluate our cross-lingual data selection method on NMT across five diverse domains in three language pairs, as well as a real-world scenario of translation for COVID-19. The results show that our proposed method outperforms other selection baselines up to +1.5 BLEU score.
翻译:本文件考虑了神经机器翻译(NMT)的未经监督的域适应问题, 我们假设在新域中只能使用源语言或目标语言的单一语言文本。 我们提议了一种跨语言的数据选择方法, 从大通用单一语言的文体中提取缺失语言侧的部内句。 我们建议的方法通过对比学习,在多语种BERT之上培养适应层, 以调和源语言和目标语言的表达方式。 这样可以让域分类器在语言之间以零发方式转换。 一旦分类器检测到内部数据, NMT 模式就会通过联合学习翻译和域内歧视任务来适应新域。 我们用三对语言来评估我们关于NMT五个不同域的跨语言数据选择方法, 以及COVID-19的翻译真实世界情景。 结果显示, 我们的拟议方法超越了其他选择基线, 直至 +1.5 BLEU 分。