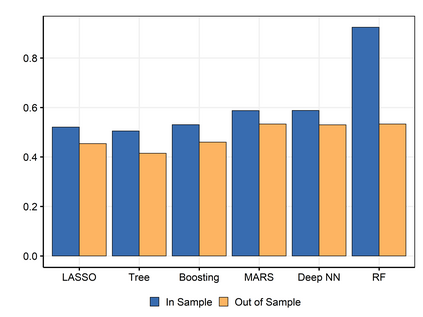
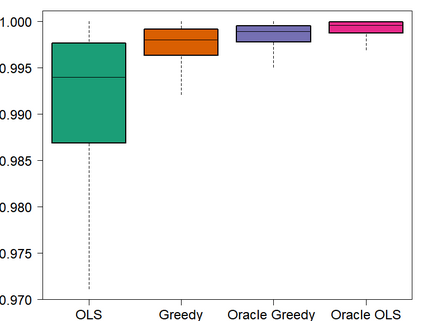
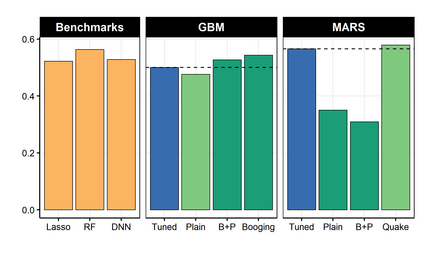
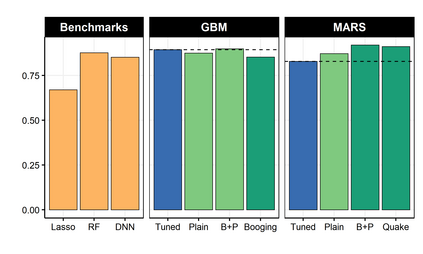
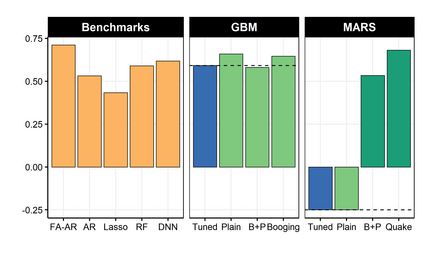
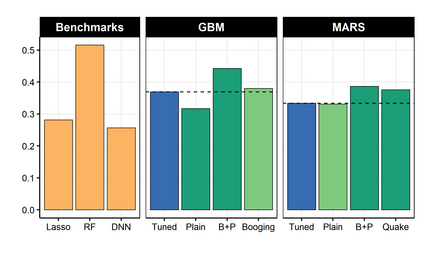
It is notoriously difficult to build a bad Random Forest (RF). Concurrently, RF is perhaps the only standard ML algorithm that blatantly overfits in-sample without any consequence out-of-sample. Standard arguments cannot rationalize this paradox. I propose a new explanation: bootstrap aggregation and model perturbation as implemented by RF automatically prune a (latent) true underlying tree. More generally, randomized ensembles of greedily optimized learners implicitly perform optimal early stopping out-of-sample. So there is no need to tune the stopping point. By construction, variants of Boosting and MARS are also eligible for automatic tuning. I empirically demonstrate the property, with simulated and real data, by reporting that these new completely overfitting ensembles yield an out-of-sample performance equivalent to that of their tuned counterparts -- or better.
翻译:造一个坏的随机森林(RF)是众所周知的困难。 同时, RF或许是唯一的标准 ML 算法,它明显地在标本中夸夸其谈,而不会产生任何结果。 标准论据不能使这一悖论合理化。 我提议新的解释: 由 RF 实施的靴套集和模型扰动自动( 相对的) 根植树。 更一般地说, 贪婪的优化学习者随机集成暗含了最佳的早期停止采样。 因此, 没有必要调整停放点。 通过构建, 博彩和MARS的变种也有资格自动调整。 我用模拟和真实的数据, 实证地展示了这些特性, 以模拟和真实的数据, 通过报告这些新式的完全超配的组合产生相当于其调整的对应方( 或更好) 的外观性能。