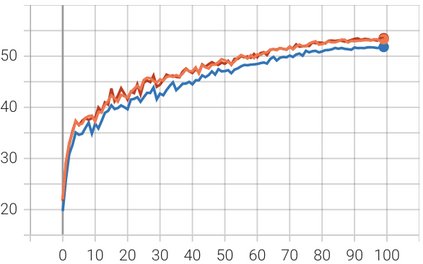
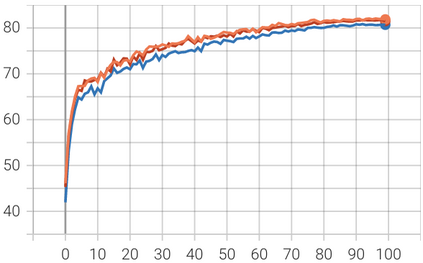
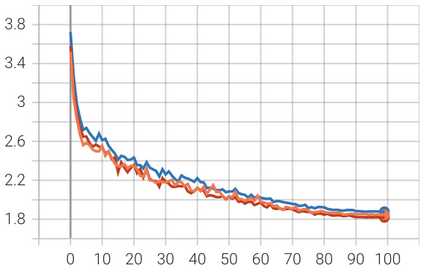
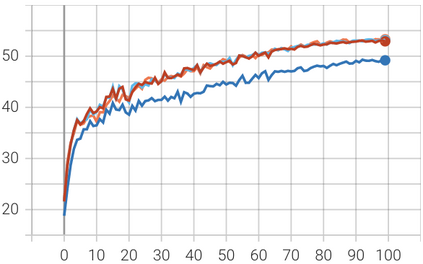
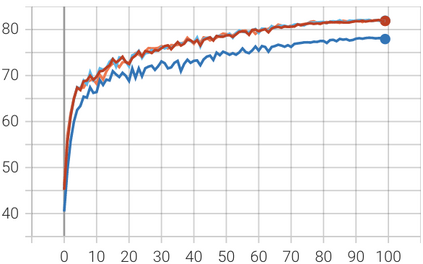
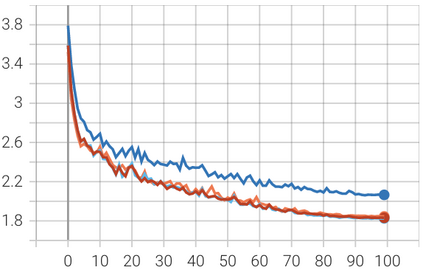
In this paper, we introduce Attention Prompt Tuning (APT) - a computationally efficient variant of prompt tuning for video-based applications such as action recognition. Prompt tuning approaches involve injecting a set of learnable prompts along with data tokens during fine-tuning while keeping the backbone frozen. This approach greatly reduces the number of learnable parameters compared to full tuning. For image-based downstream tasks, normally a couple of learnable prompts achieve results close to those of full tuning. However, videos, which contain more complex spatiotemporal information, require hundreds of tunable prompts to achieve reasonably good results. This reduces the parameter efficiency observed in images and significantly increases latency and the number of floating-point operations (FLOPs) during inference. To tackle these issues, we directly inject the prompts into the keys and values of the non-local attention mechanism within the transformer block. Additionally, we introduce a novel prompt reparameterization technique to make APT more robust against hyperparameter selection. The proposed APT approach greatly reduces the number of FLOPs and latency while achieving a significant performance boost over the existing parameter-efficient tuning methods on UCF101, HMDB51, and SSv2 datasets for action recognition. The code and pre-trained models are available at https://github.com/wgcban/apt
翻译:暂无翻译