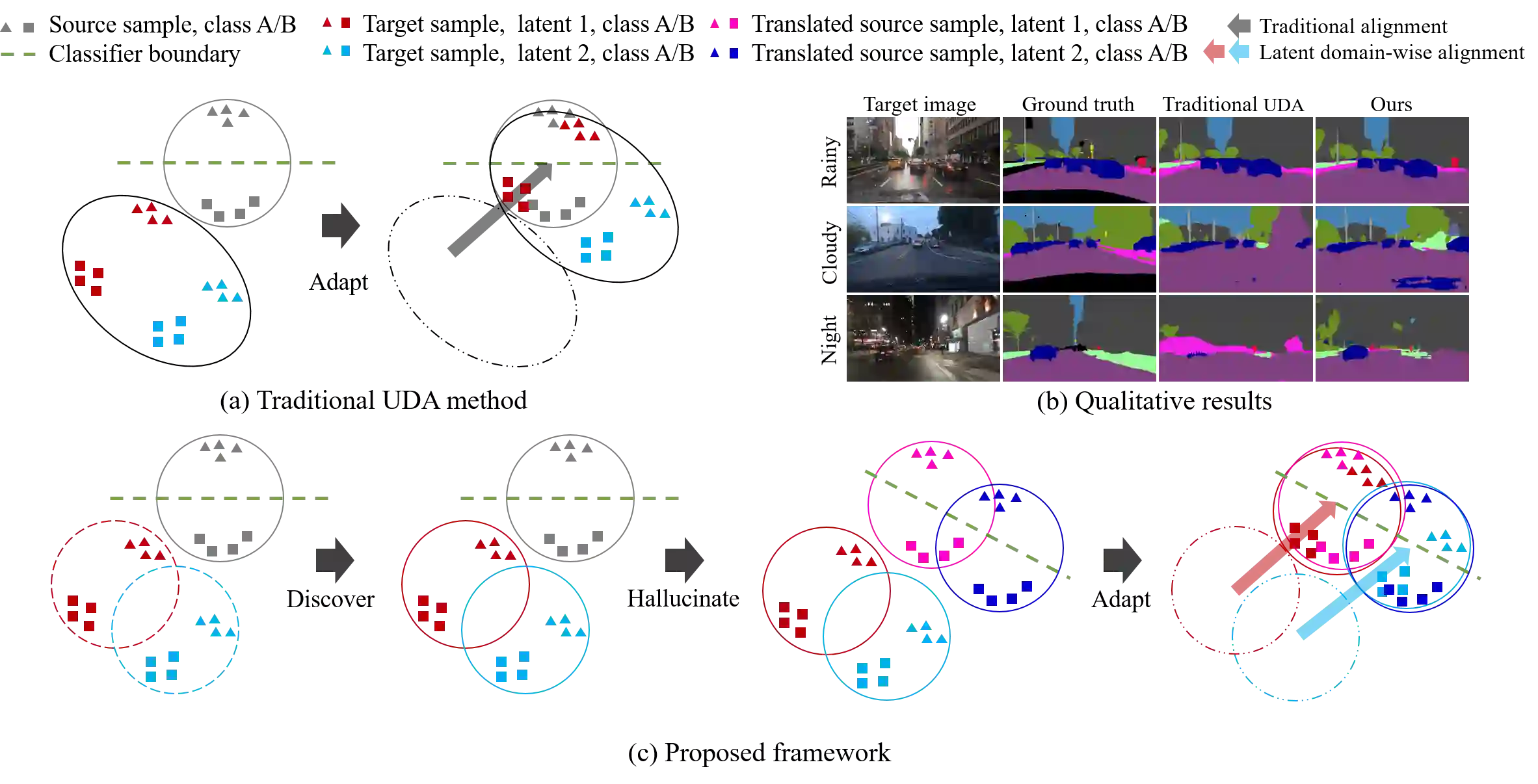
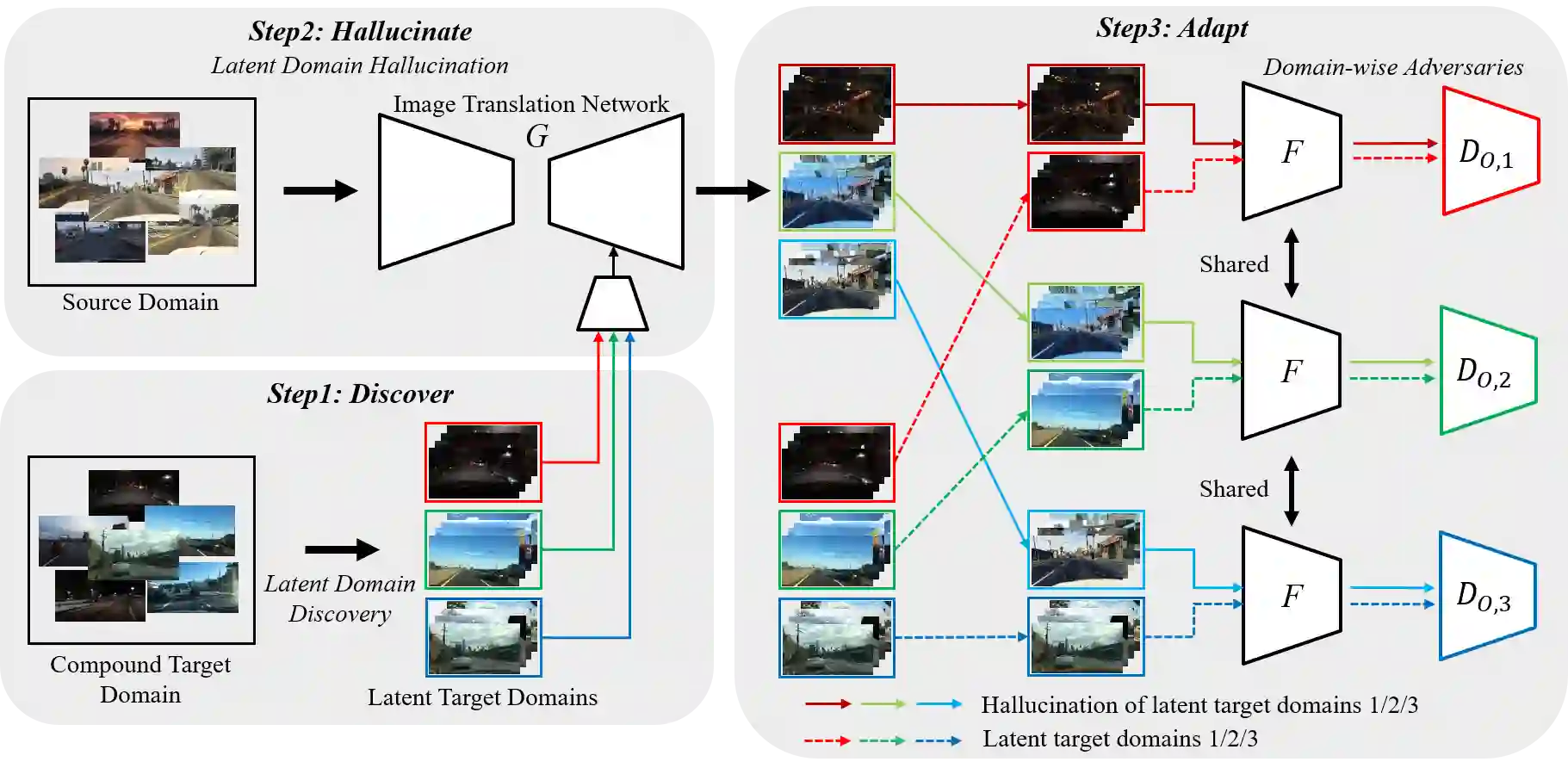
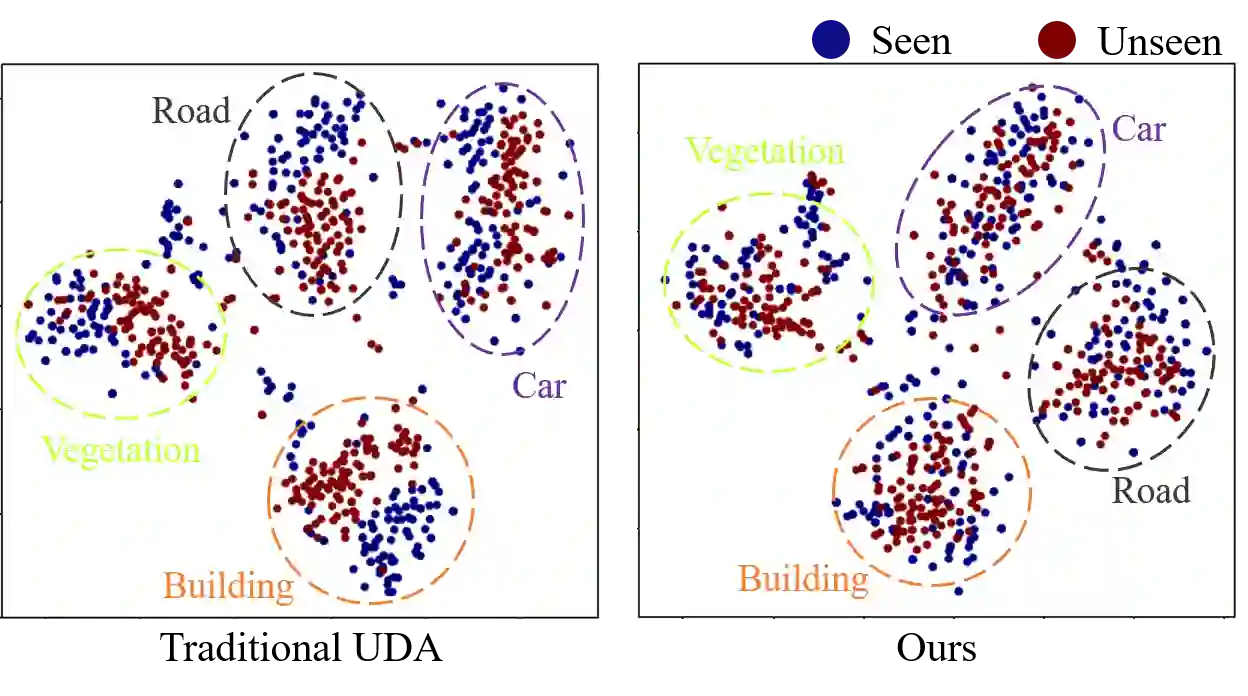
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
翻译:用于语义分解的未受监督域适应(UDA)最近引起注意,因为它可能有益于各种标签偏差现实世界情景(例如,机器人控制、自主驾驶、医疗成像等)。尽管在这一领域取得了显著进展,但目前的工作主要侧重于单一源单一目标设置,无法处理多个目标甚至看不见目标更实际的设置。在本文件中,我们调查了同时处理混合和新情况、用于语义分解的开放复合域适应(OCDA),我们提出了一个基于三大主要设计原则的新框架:发现、幻觉和适应。这个方案首先组群集基于风格、发现多个潜在领域(发现)的组合目标数据。然后,它通过图像转换(光栅)在源中产生多种潜在目标领域幻觉。这个步骤确保源和目标对齐的隐蔽领域。最后,目标对源调整是在不同领域(适应)分别学习的。在高层次上,我们的解决办法取代了硬性 OCDA 问题,以更简单得多的标准UDA 。