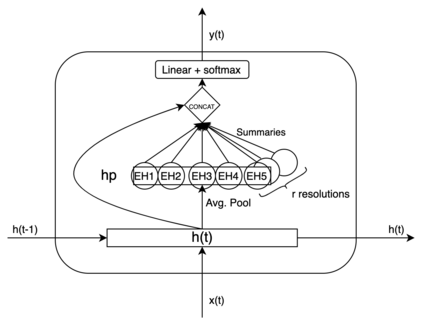
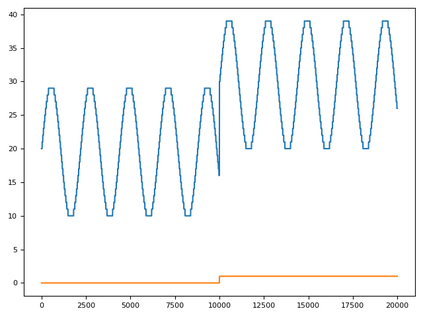
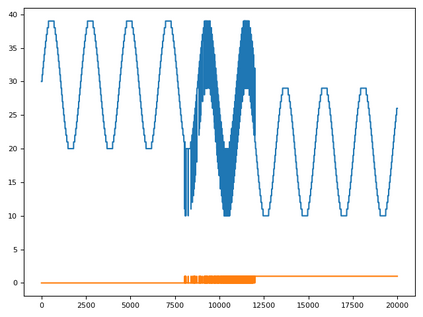
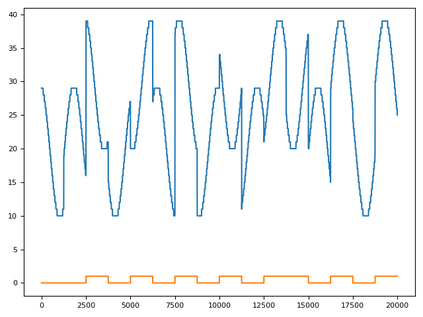
Time series data can be subject to changes in the underlying process that generates them and, because of these changes, models built on old samples can become obsolete or perform poorly. In this work, we present a way to incorporate information about the current data distribution and its evolution across time into machine learning algorithms. Our solution is based on efficiently maintaining statistics, particularly the mean and the variance, of data features at different time resolutions. These data summarisations can be performed over the input attributes, in which case they can then be fed into the model as additional input features, or over latent representations learned by models, such as those of Recurrent Neural Networks. In classification tasks, the proposed techniques can significantly outperform the prediction capabilities of equivalent architectures with no feature / latent summarisations. Furthermore, these modifications do not introduce notable computational and memory overhead when properly adjusted.
翻译:时间序列数据可能会随着生成数据的基本过程的变化而变化,而且由于这些变化,以旧样品为基础的模型可能会过时或表现不佳。在这项工作中,我们提出一种方法,将关于当前数据分布及其在时间上的演变的信息纳入机器学习算法。我们的解决办法是在不同时间分辨率的数据特征方面有效地维持统计数据,特别是平均值和差异。这些数据汇总可以针对输入属性进行,然后可以作为额外的输入特征输入模型,或者通过模型(例如经常性神经网络的模型)获得的潜在表现。在分类任务中,拟议的技术可以大大超过没有特征/潜在汇总的等同结构的预测能力。此外,这些修改在适当调整时不会引入显著的计算和记忆管理。