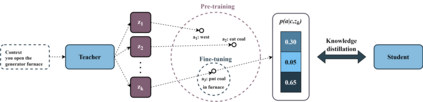
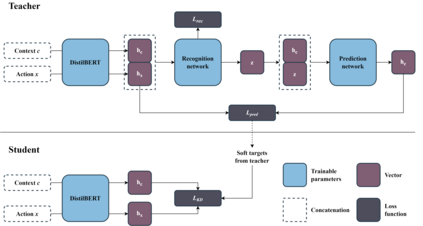
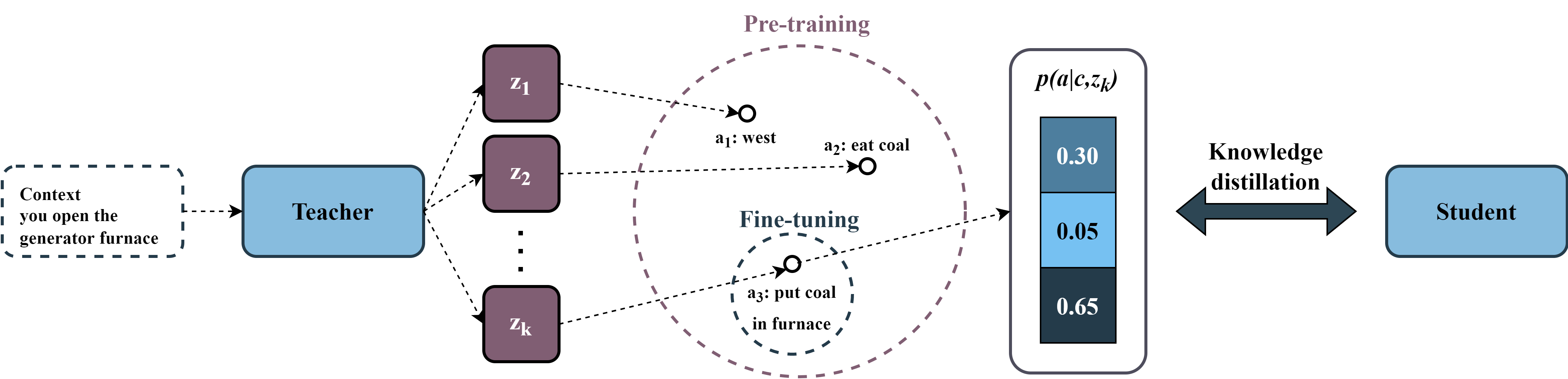
Language models pre-trained on large self-supervised corpora, followed by task-specific fine-tuning has become the dominant paradigm in NLP. These pre-training datasets often have a one-to-many structure--e.g. in dialogue there are many valid responses for a given context. However, only some of these responses will be desirable in our downstream task. This raises the question of how we should train the model such that it can emulate the desirable behaviours, but not the undesirable ones. Current approaches train in a one-to-one setup--only a single target response is given for a single dialogue context--leading to models only learning to predict the average response, while ignoring the full range of possible responses. Using text-based games as a testbed, our approach, PASA, uses discrete latent variables to capture the range of different behaviours represented in our larger pre-training dataset. We then use knowledge distillation to distil the posterior probability distribution into a student model. This probability distribution is far richer than learning from only the hard targets of the dataset, and thus allows the student model to benefit from the richer range of actions the teacher model has learned. Results show up to 49% empirical improvement over the previous state-of-the-art model on the Jericho Walkthroughs dataset.
翻译:在自然语言处理(NLP)中,预训练的语言模型后跟任务特定的微调已成为主流范式。这些预训练数据集通常具有一对多的结构-例如,在对话中,对于给定的上下文,有许多有效的回应。然而,只有其中一些回应在下游任务中是可取的。这引出了一个问题,即我们应该如何训练模型,使其能够模仿可取的行为,但不是不可取的行为。当前的方法在一对一的设置中进行训练--对于单个对话上下文只给出一个目标回应--导致模型只学习预测平均回应,而忽略了可能的所有回应。使用基于文本的游戏作为测试平台,我们的方法PASA使用离散的隐变量来捕捉我们较大的预训练数据集中呈现出的不同行为范围。然后,我们使用知识蒸馏将后验概率分布蒸馏成学生模型。这个概率分布比仅从数据集的硬目标学习要丰富得多,因此允许学生模型从老师模型学到更丰富的行为范围。结果显示,在Jericho Walkthroughs数据集上,与之前的最先进模型相比,获得了多达49%的实证改进。