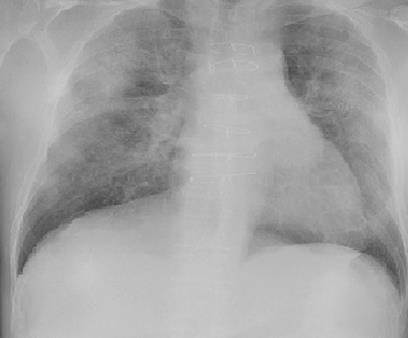
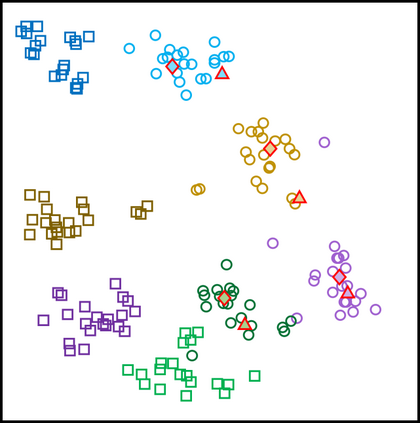
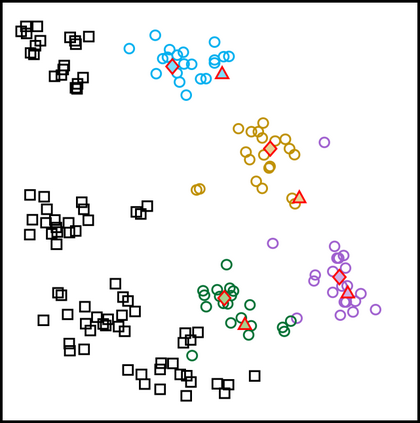
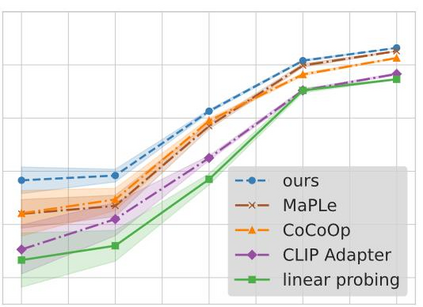
In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
翻译:暂无翻译