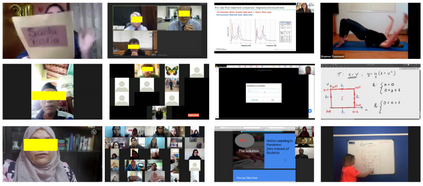
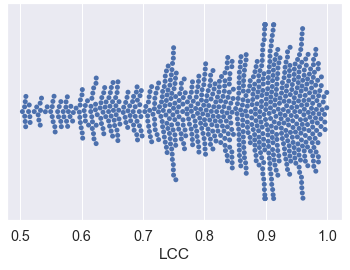
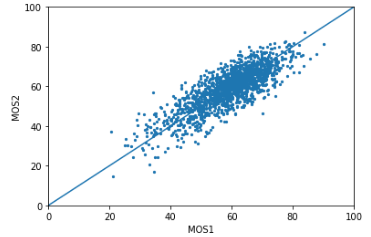
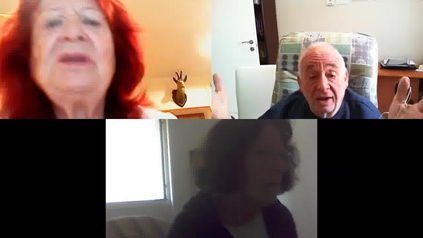
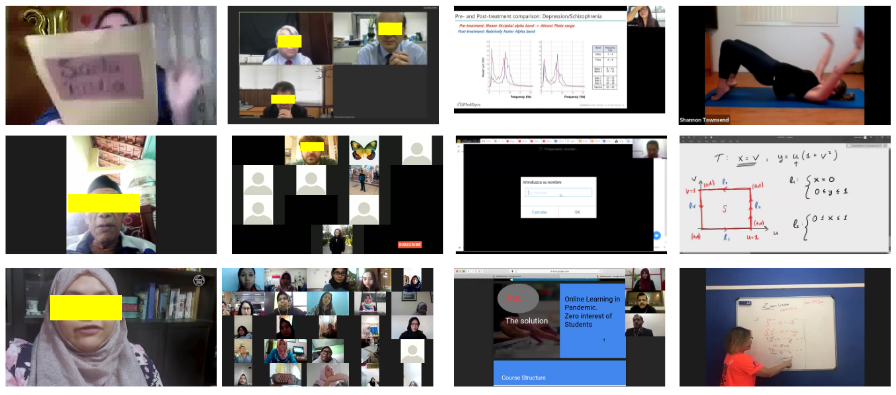
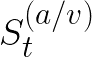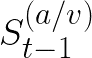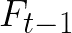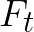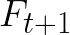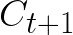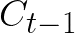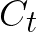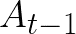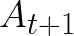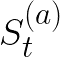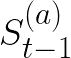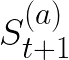Video conferencing, which includes both video and audio content, has contributed to dramatic increases in Internet traffic, as the COVID-19 pandemic forced millions of people to work and learn from home. Global Internet traffic of video conferencing has dramatically increased Because of this, efficient and accurate video quality tools are needed to monitor and perceptually optimize telepresence traffic streamed via Zoom, Webex, Meet, etc. However, existing models are limited in their prediction capabilities on multi-modal, live streaming telepresence content. Here we address the significant challenges of Telepresence Video Quality Assessment (TVQA) in several ways. First, we mitigated the dearth of subjectively labeled data by collecting ~2k telepresence videos from different countries, on which we crowdsourced ~80k subjective quality labels. Using this new resource, we created a first-of-a-kind online video quality prediction framework for live streaming, using a multi-modal learning framework with separate pathways to compute visual and audio quality predictions. Our all-in-one model is able to provide accurate quality predictions at the patch, frame, clip, and audiovisual levels. Our model achieves state-of-the-art performance on both existing quality databases and our new TVQA database, at a considerably lower computational expense, making it an attractive solution for mobile and embedded systems.
翻译:包括视频和音频内容在内的视频会议使互联网流量急剧增加,因为COVID-19大流行病迫使数百万人在家里工作并学习。全球互联网视频会议流量急剧增加,全球互联网视频会议流量急剧增加,为此,需要高效和准确的视频质量工具来监测和感知优化通过Zoom、Webex、Meet等传输的远程直播流量。然而,现有模型在多模式、现场流传远程现场内容方面的预测能力有限。这里我们以几种方式应对远程现场视频质量评估(TVQA)的重大挑战。首先,我们通过收集来自不同国家的~2k远程视频频谱路面视频来减轻主观标签数据损失,我们把这种视频高效和准确的视频质量工具集中到~80k主观质量标签上。然而,我们利用这一新资源,为现场流流信息创建了首个首个友好的在线视频质量视频质量预测框架,同时采用多种模式,以不同的路径来理解视频和音频质量预测。我们的所有模型能够提供准确的质量预测,在新的视频数据库、低级上,在高额的存储成本数据库上,实现一个具有吸引力的、高额的、高额成本的版本数据库。