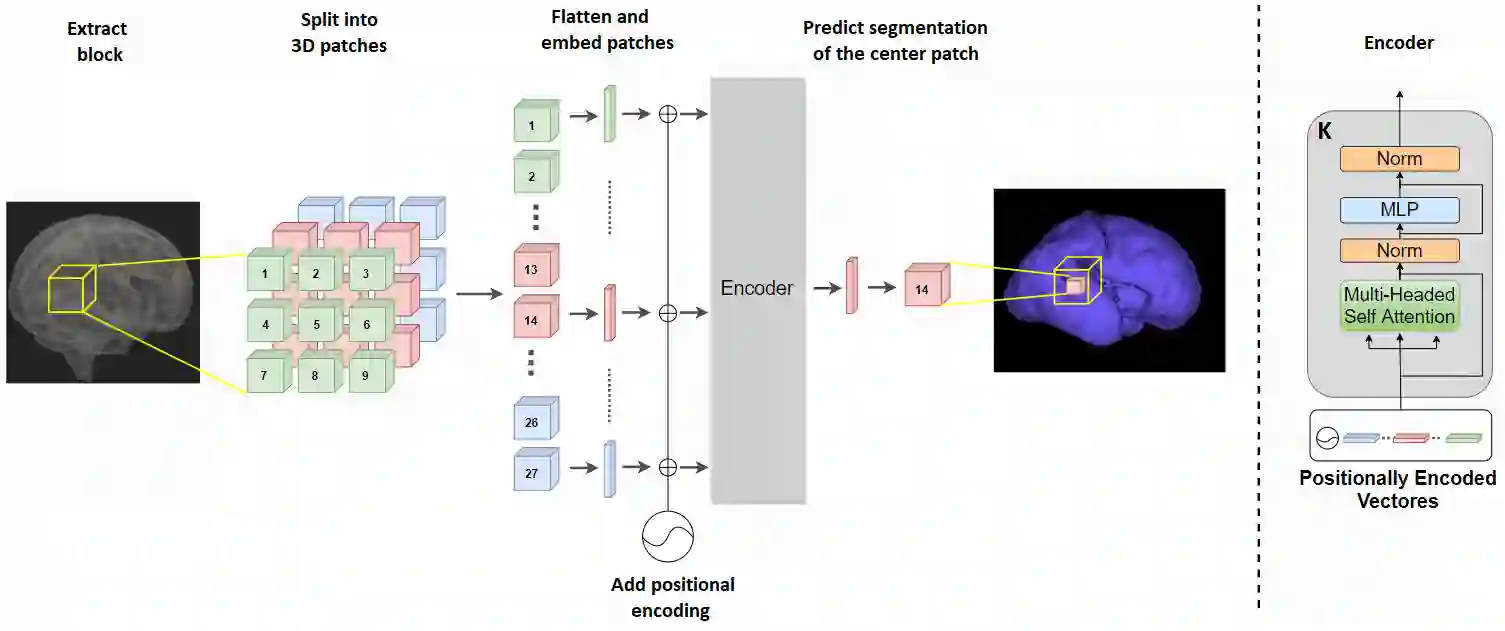
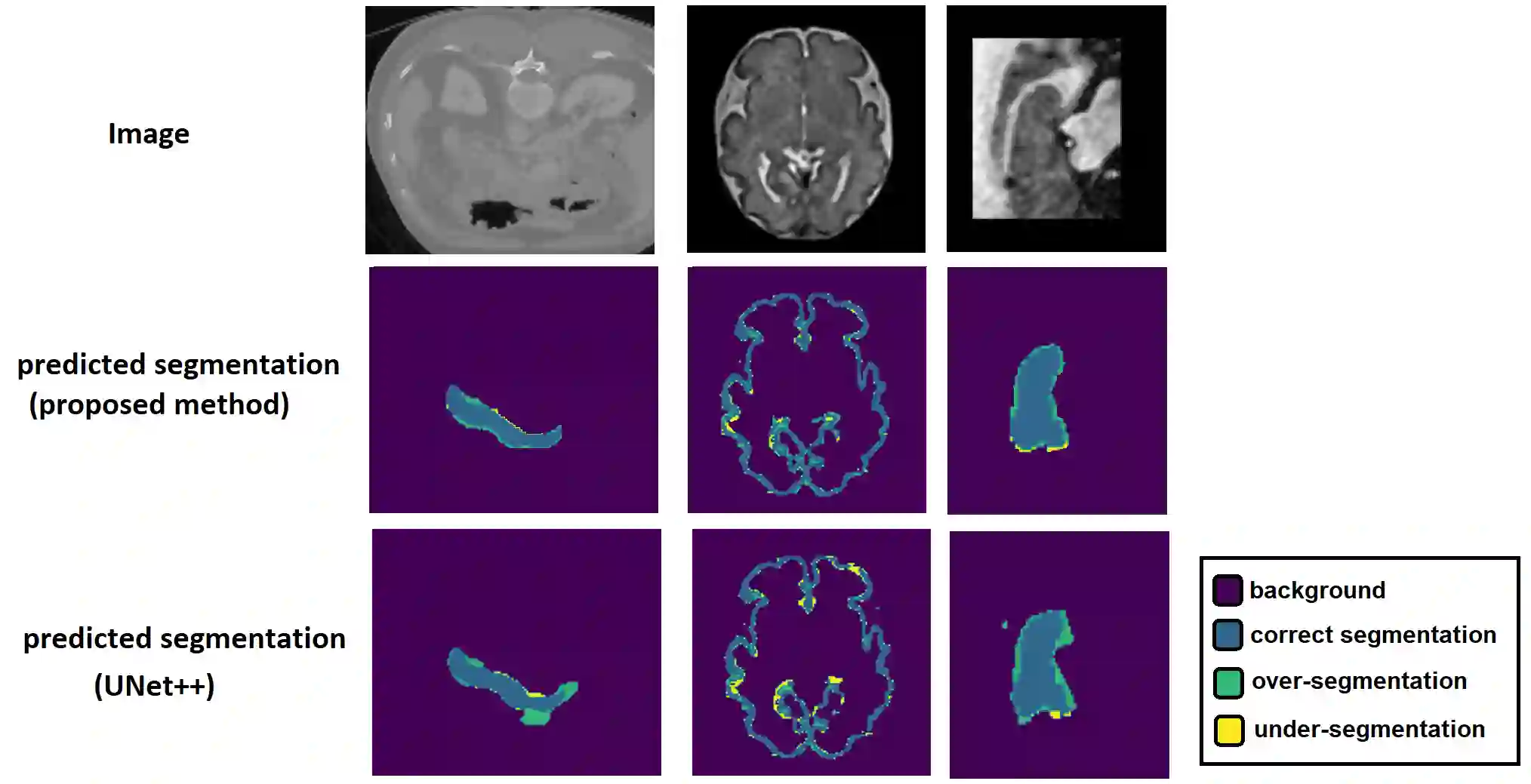
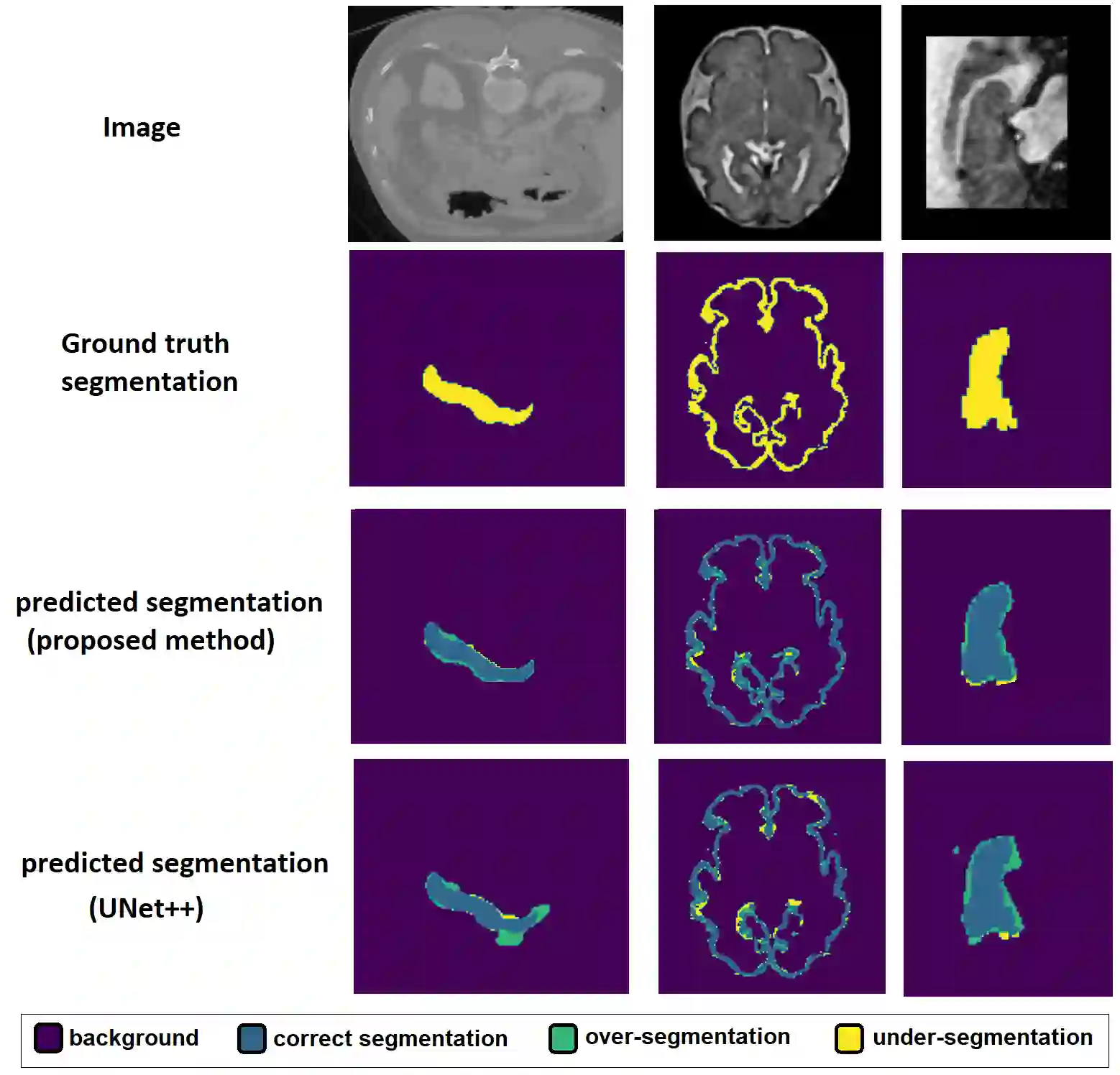
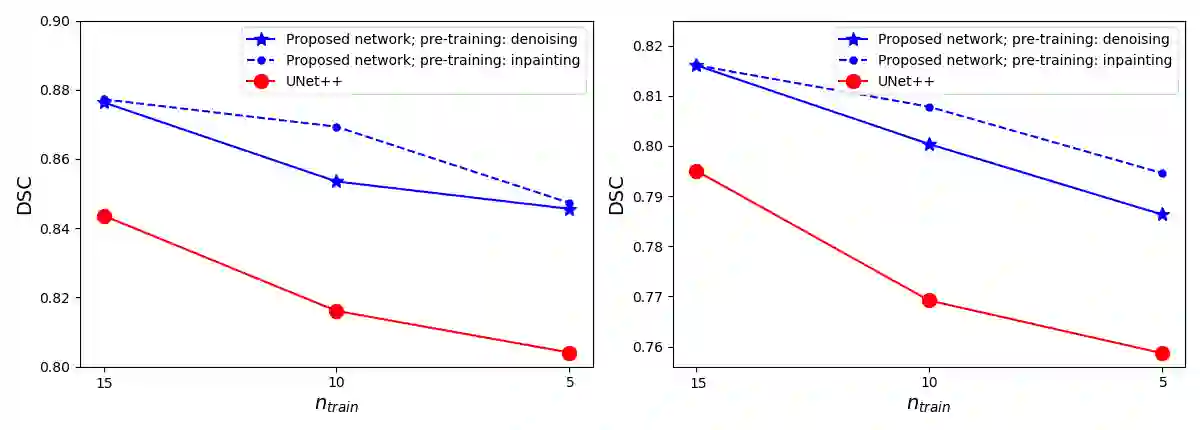
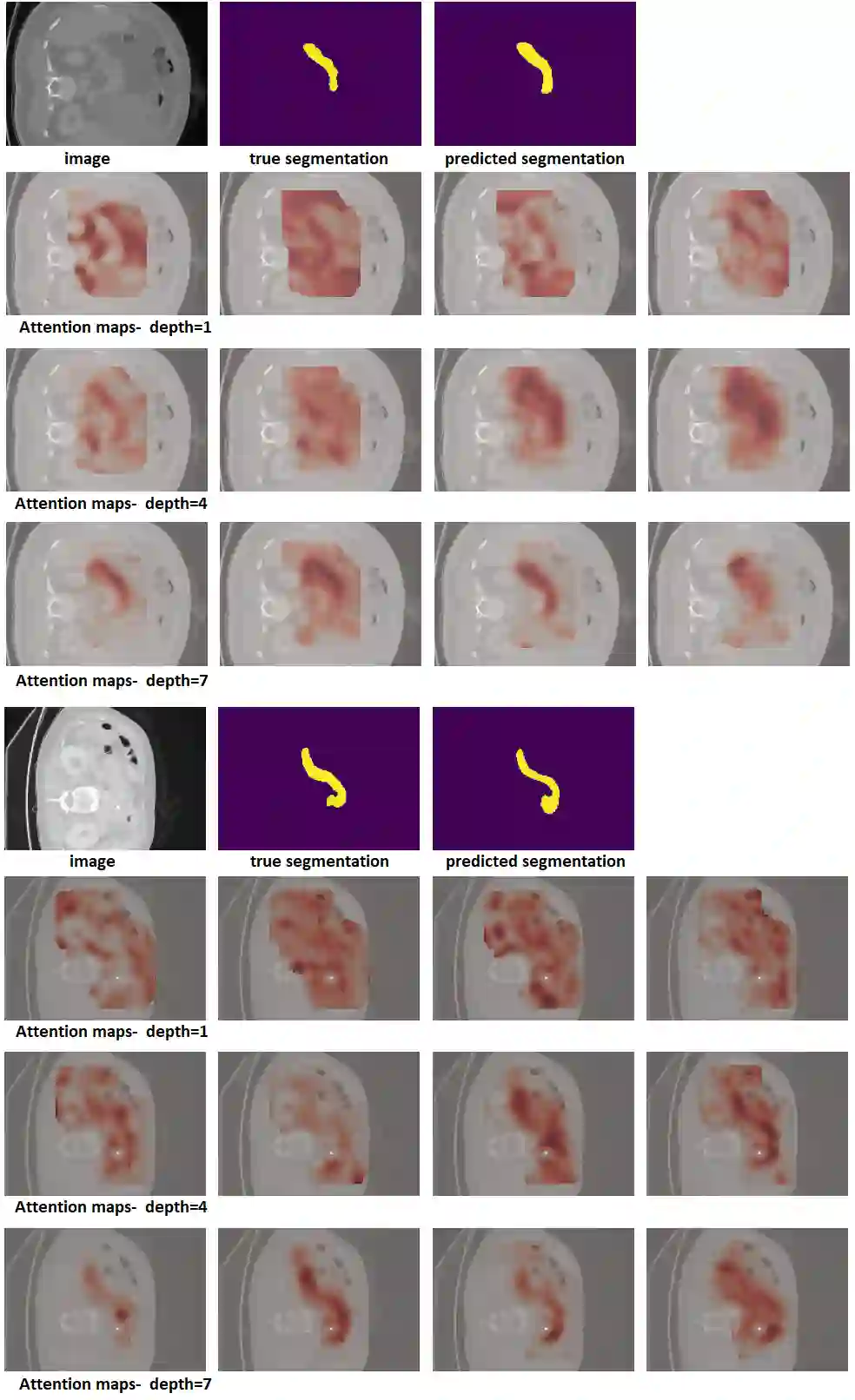
Like other applications in computer vision, medical image segmentation has been most successfully addressed using deep learning models that rely on the convolution operation as their main building block. Convolutions enjoy important properties such as sparse interactions, weight sharing, and translation equivariance. These properties give convolutional neural networks (CNNs) a strong and useful inductive bias for vision tasks. In this work we show that a different method, based entirely on self-attention between neighboring image patches and without any convolution operations, can achieve competitive or better results. Given a 3D image block, our network divides it into $n^3$ 3D patches, where $n=3 \text{ or } 5$ and computes a 1D embedding for each patch. The network predicts the segmentation map for the center patch of the block based on the self-attention between these patch embeddings. We show that the proposed model can achieve segmentation accuracies that are better than the state of the art CNNs on three datasets. We also propose methods for pre-training this model on large corpora of unlabeled images. Our experiments show that with pre-training the advantage of our proposed network over CNNs can be significant when labeled training data is small.
翻译:与计算机视觉中的其他应用一样, 医疗图像分割是最成功的处理方法, 使用依靠卷土重来作业作为主要构件的深层次学习模型。 革命享有重要属性, 如: 低度互动、 重量共享和翻译等。 这些属性为视觉任务提供了强烈而有用的导导导偏。 在这项工作中, 我们显示完全基于相邻图像补接合点之间自知的、 没有卷土重来操作的另一种方法可以实现竞争性或更好的效果。 3D 图像块, 我们的网络将其分为3D 3D 块, 即 $=3\ text{ 或} 5$, 并且为每个补丁构建一个 1D 嵌入。 网络预测了基于这些补布嵌入点之间自知的区块中心段图。 我们显示, 拟议的模型可以实现比三个数据集上的艺术 CNN 状态更好的分解。 我们还建议了在大型网络上预先训练这个模型的方法, 也就是在未贴标签的图像上显示我们所建的标签前的优势。