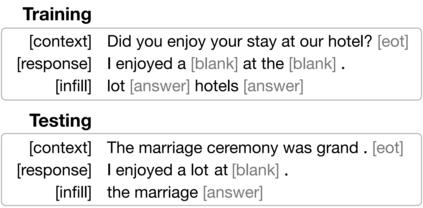
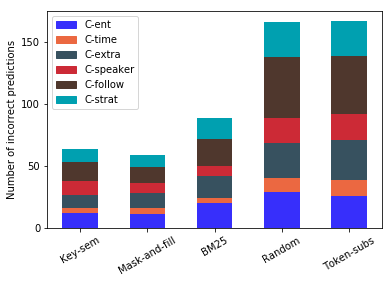
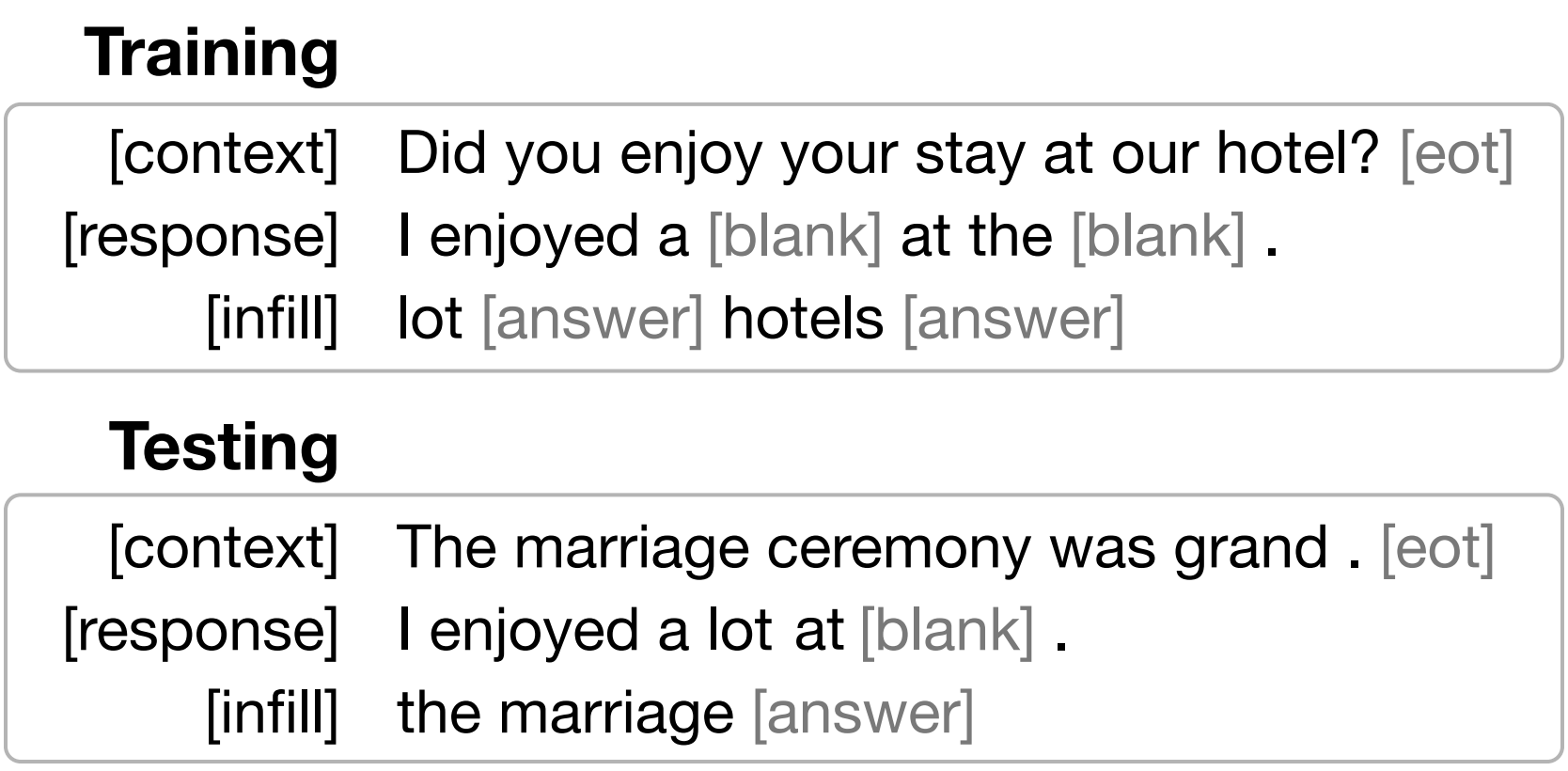
Open-domain neural dialogue models have achieved high performance in response ranking and evaluation tasks. These tasks are formulated as a binary classification of responses given in a dialogue context, and models generally learn to make predictions based on context-response content similarity. However, over-reliance on content similarity makes the models less sensitive to the presence of inconsistencies, incorrect time expressions and other factors important for response appropriateness and coherence. We propose approaches for automatically creating adversarial negative training data to help ranking and evaluation models learn features beyond content similarity. We propose mask-and-fill and keyword-guided approaches that generate negative examples for training more robust dialogue systems. These generated adversarial responses have high content similarity with the contexts but are either incoherent, inappropriate or not fluent. Our approaches are fully data-driven and can be easily incorporated in existing models and datasets. Experiments on classification, ranking and evaluation tasks across multiple datasets demonstrate that our approaches outperform strong baselines in providing informative negative examples for training dialogue systems.
翻译:开放式神经对话模式在响应等级和评价工作中取得了很高的成绩,这些任务是作为对话背景下所作反应的二分分类,通常用来根据背景反应内容相似性作出预测。然而,过分依赖内容相似性使得对内容的过分依赖对不一致、不正确的时间表达方式和对回应适当性和一致性十分重要的其他因素不那么敏感。我们建议了自动创建对抗式负面培训数据的方法,以帮助对立式的负面培训数据学习内容相似性以外的特征。我们提出了为培训更健全的对话系统提供负面实例的掩码和关键词指导方法。这些生成的对抗性答复在内容上与情况非常相似,但不连贯、不适当或不流利。我们的方法完全以数据为驱动,很容易纳入现有的模型和数据集。关于多个数据集的分类、排位和评价工作的实验表明,我们的方法在为培训对话系统提供信息化负面实例方面超越了强有力的基线。