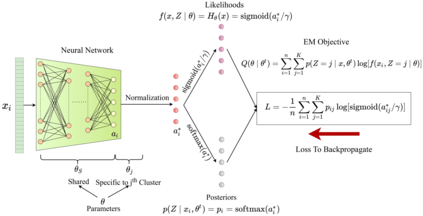
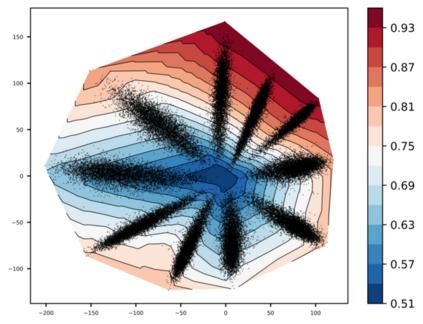
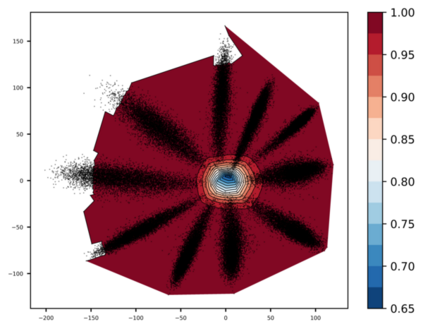
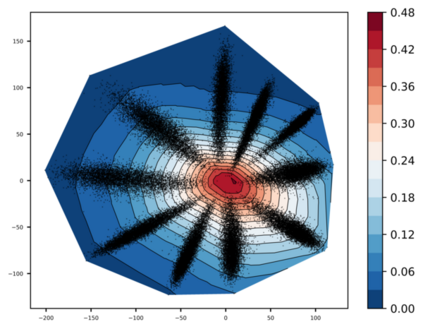
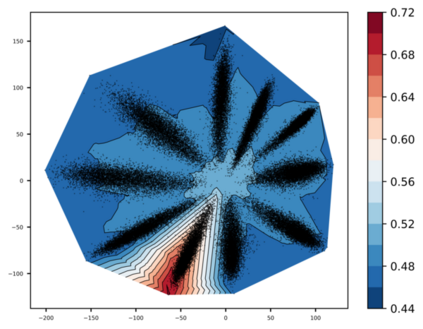
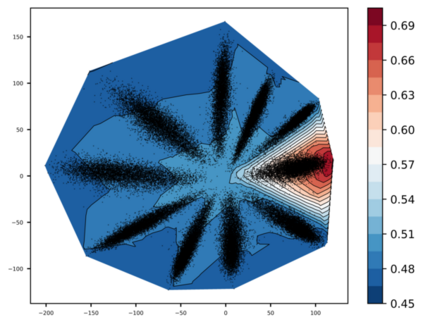
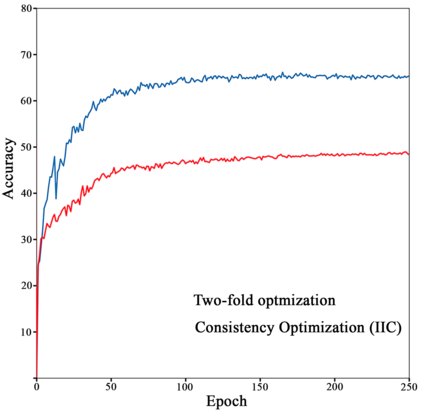
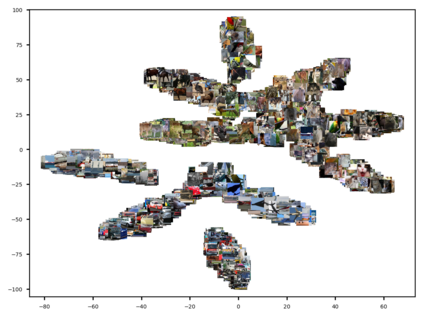
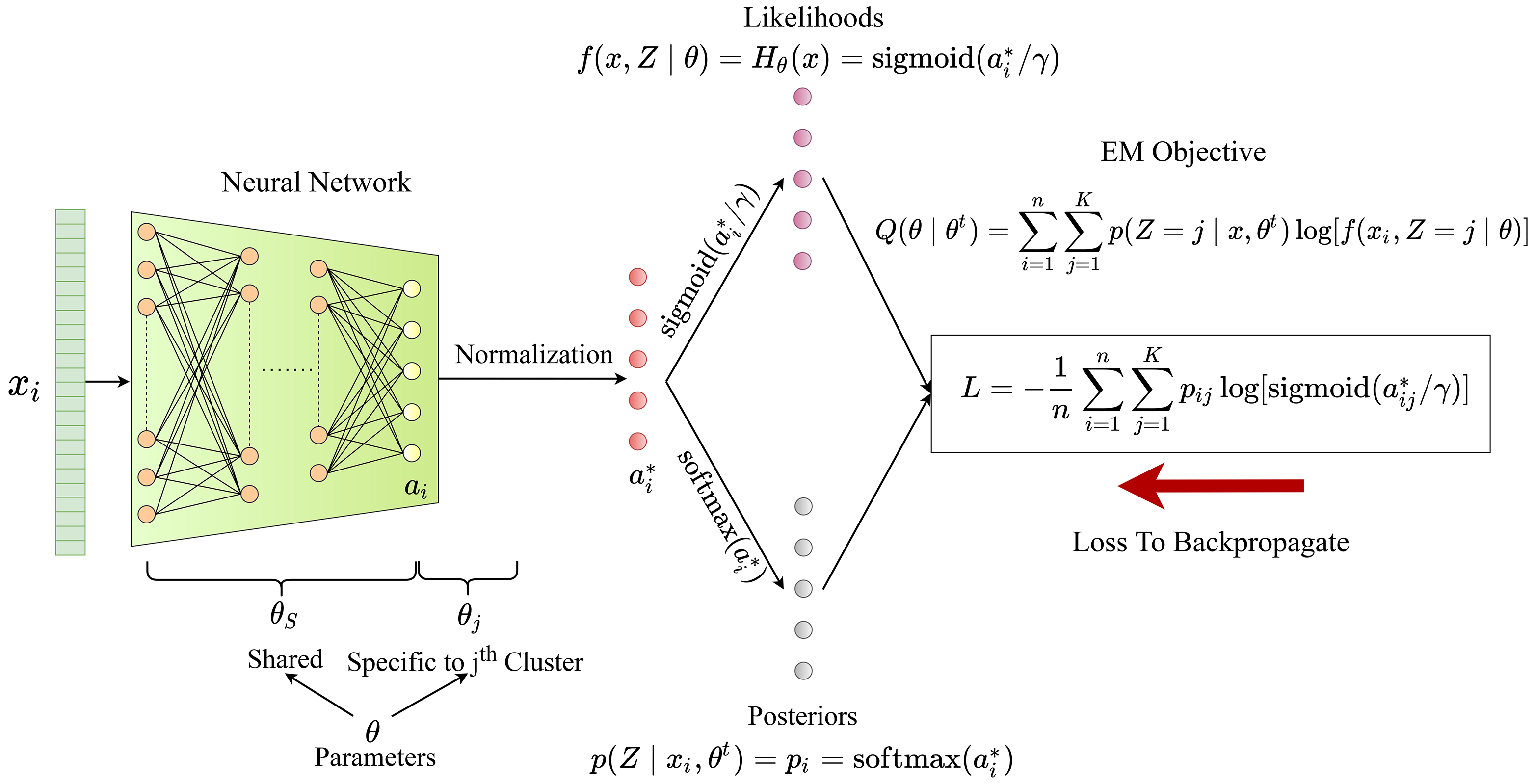
Any clustering algorithm must synchronously learn to model the clusters and allocate data to those clusters in the absence of labels. Mixture model-based methods model clusters with pre-defined statistical distributions and allocate data to those clusters based on the cluster likelihoods. They iteratively refine those distribution parameters and member assignments following the Expectation-Maximization (EM) algorithm. However, the cluster representability of such hand-designed distributions that employ a limited amount of parameters is not adequate for most real-world clustering tasks. In this paper, we realize mixture model-based clustering with a neural network where the final layer neurons, with the aid of an additional transformation, approximate cluster distribution outputs. The network parameters pose as the parameters of those distributions. The result is an elegant, much-generalized representation of clusters than a restricted mixture of hand-designed distributions. We train the network end-to-end via batch-wise EM iterations where the forward pass acts as the E-step and the backward pass acts as the M-step. In image clustering, the mixture-based EM objective can be used as the clustering objective along with existing representation learning methods. In particular, we show that when mixture-EM optimization is fused with consistency optimization, it improves the sole consistency optimization performance in clustering. Our trained networks outperform single-stage deep clustering methods that still depend on k-means, with unsupervised classification accuracy of 63.8% in STL10, 58% in CIFAR10, 25.9% in CIFAR100, and 98.9% in MNIST.
翻译:任何集成算法都必须同步学习模拟集群,并在没有标签的情况下将数据分配给这些集群。 以模型为基础的方法模型模型群集, 以预定义的统计分布方式为基础, 并根据集集的可能性将数据分配给这些集群组。 它们反复地完善了这些分布参数和成员在期望- 最大化(EM) 算法之后的分配任务。 然而, 使用数量有限的参数的手工设计分布的集群代表性对于大多数真实世界的集群任务来说是不够的。 在本文中, 我们意识到基于模型的组合与神经元的神经神经神经神经神经神经网络混合在一起, 借助于额外的转换, 大约的组群分布结果。 网络参数是作为这些分布的参数。 其结果是, 与限制的手工设计的分布组合组合( EM) 相比, 对这些组群集的分布参数进行了优雅和广泛化。 我们通过批量式的电解分解来培训网络端对端端到端的分布方式, 将前端10 和后端路路作为M级的依次。 在图像集中, 以混合的EM 目标可以用作最后层9.9 目标, 与现有最精确的IM IM IML IM, 在目前最优化的IM IML 中, 的 的周期化, 25, 我们用最优化的周期化的周期性,, 的周期性 的 的,,, 的 的 的 的 的 的, 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 和 的 的 的 的 的 的 的 的 的 的 的 的 的 的 和 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的 的