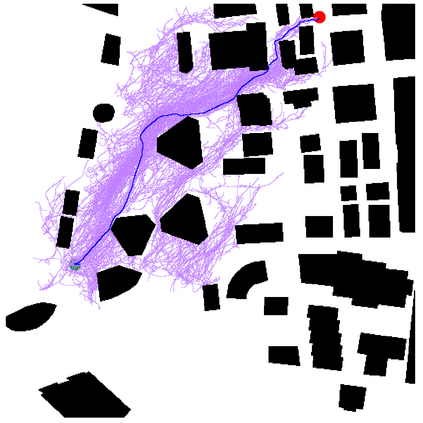
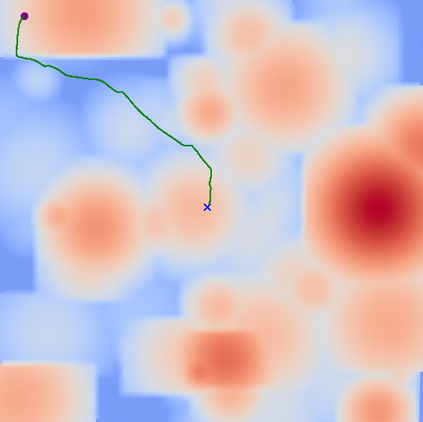
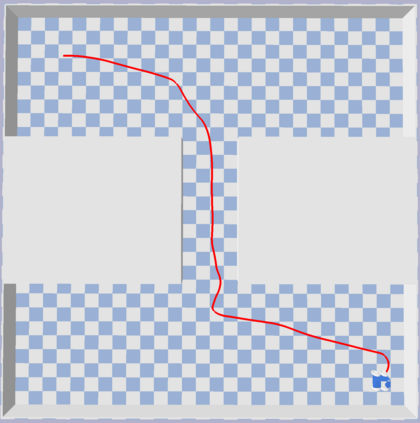
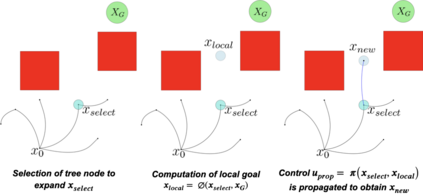
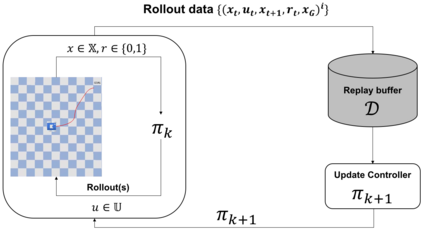
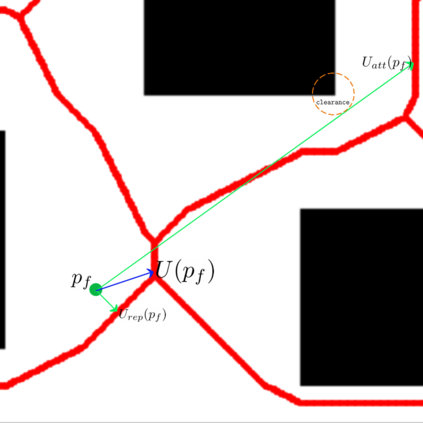
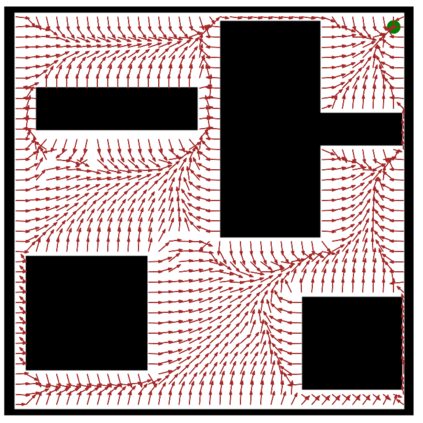
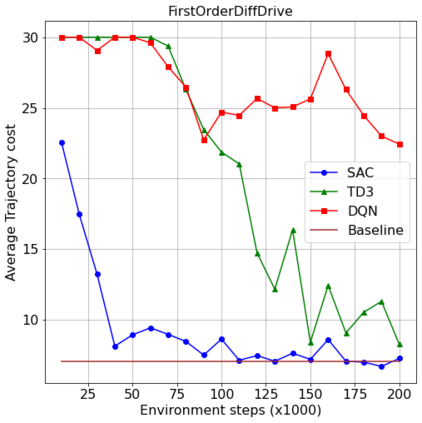
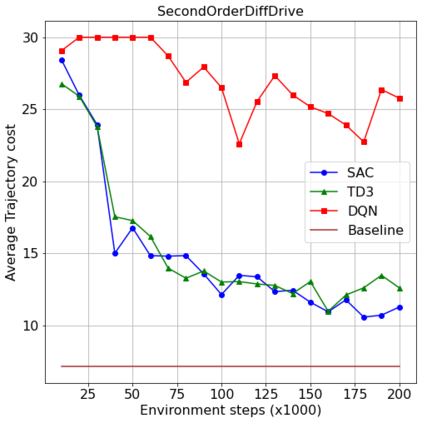
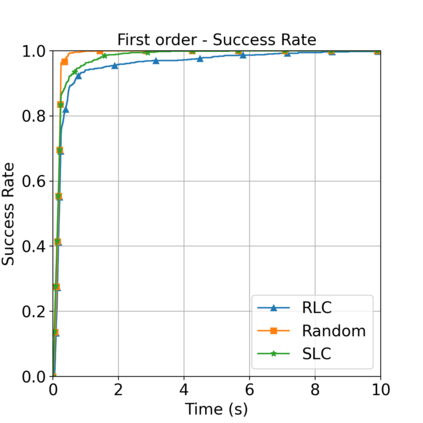
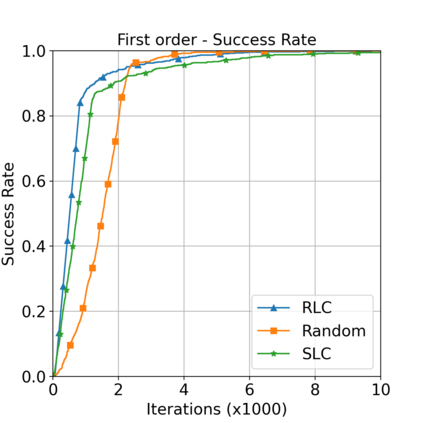
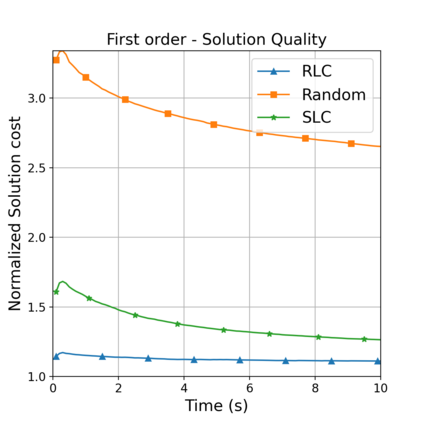
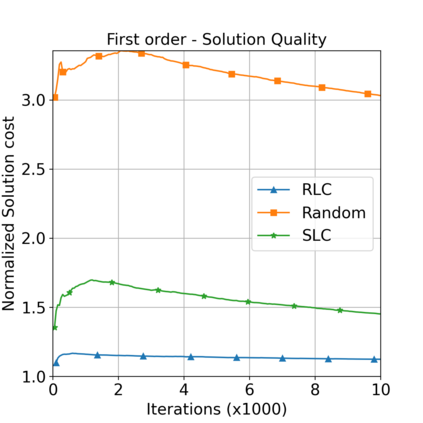
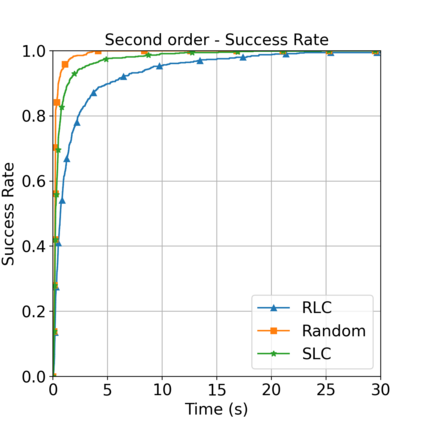
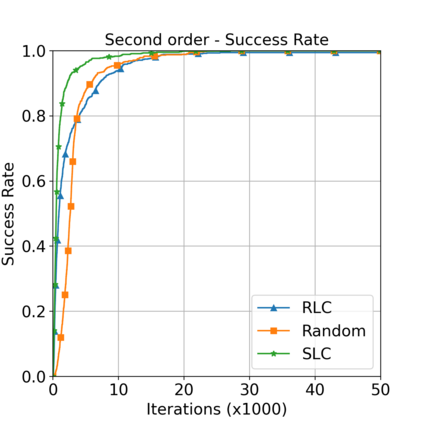
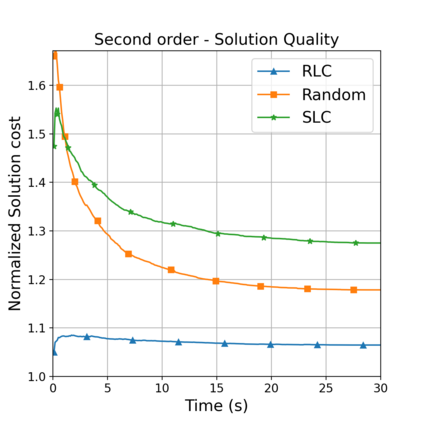
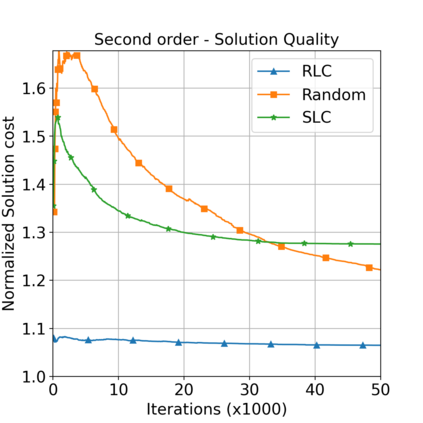
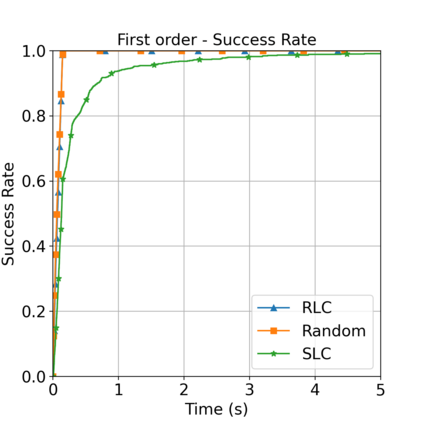
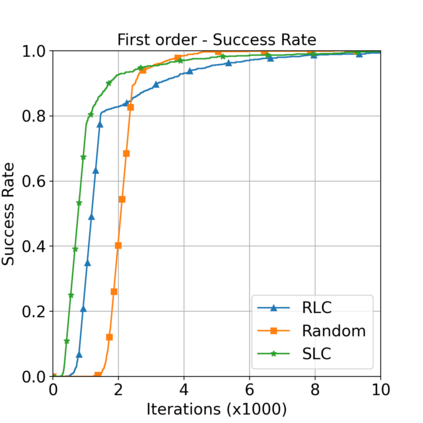
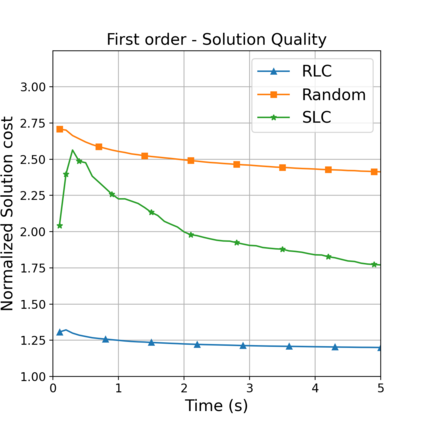
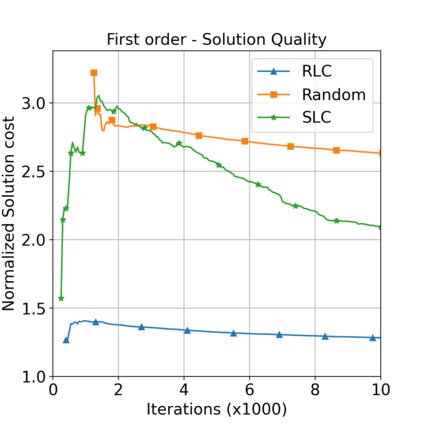
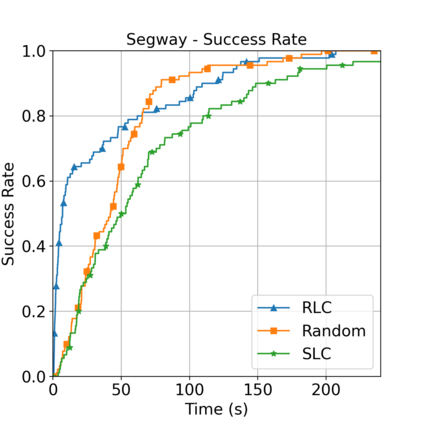
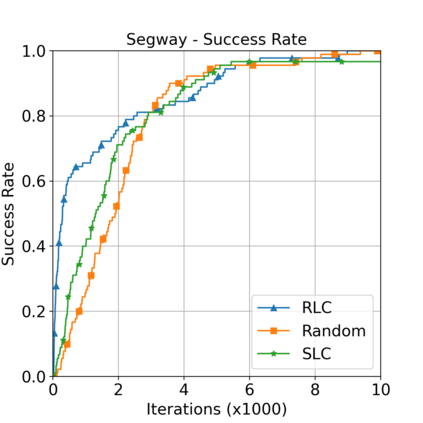
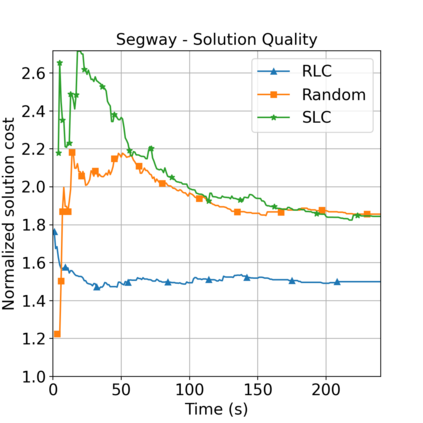
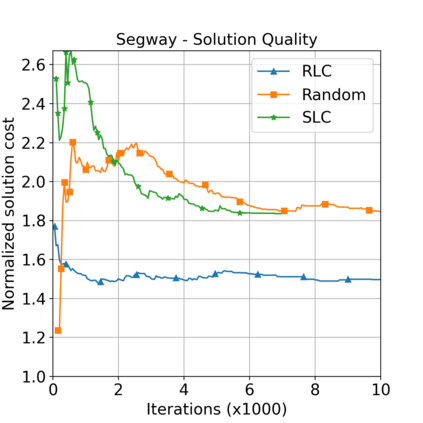
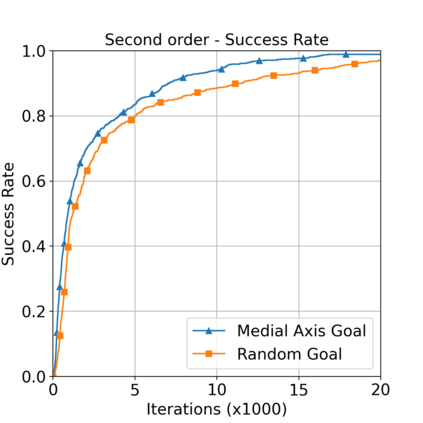
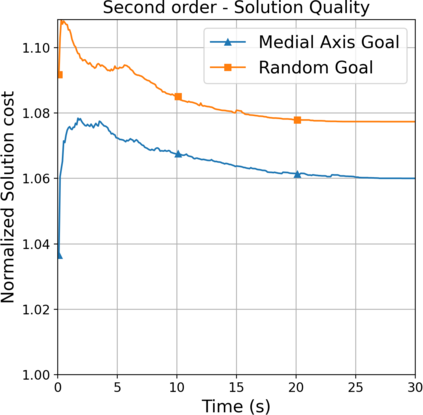
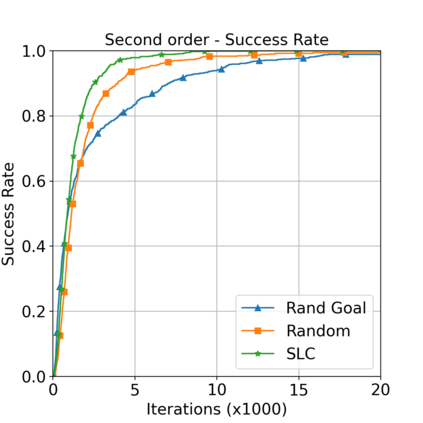
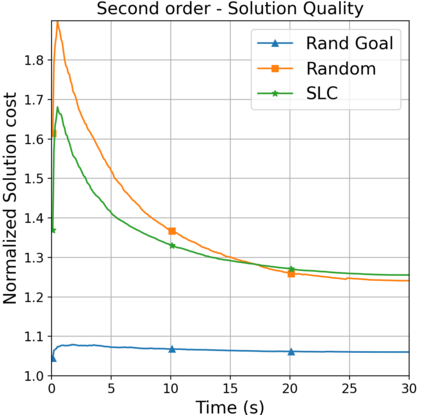
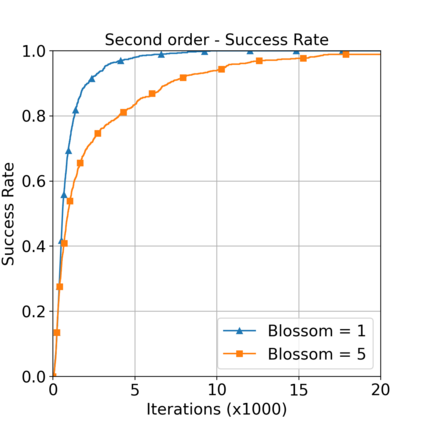
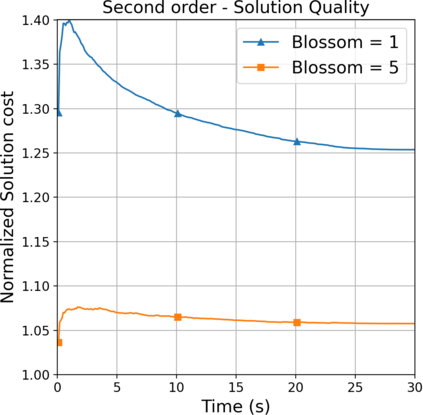
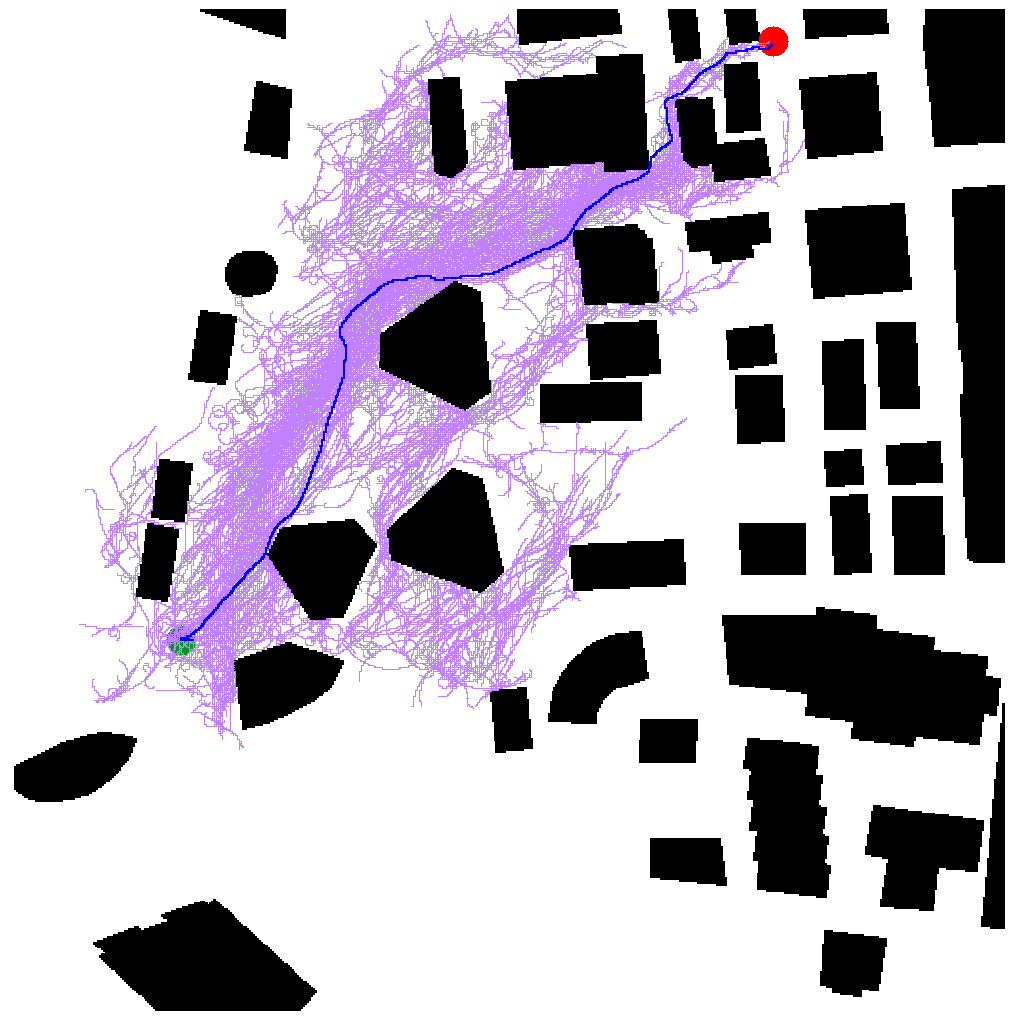
This paper aims to improve the path quality and computational efficiency of sampling-based kinodynamic planners for vehicular navigation. It proposes a learning framework for identifying promising controls during the expansion process of sampling-based planners. Given a dynamics model, a reinforcement learning process is trained offline to return a low-cost control that reaches a local goal state (i.e., a waypoint) in the absence of obstacles. By focusing on the system's dynamics and not knowing the environment, this process is data-efficient and takes place once for a robotic system. In this way, it can be reused in different environments. The planner generates online local goal states for the learned controller in an informed manner to bias towards the goal and consecutively in an exploratory, random manner. For the informed expansion, local goal states are generated either via (a) medial axis information in environments with obstacles, or (b) wavefront information for setups with traversability costs. The learning process and the resulting planning framework are evaluated for a first and second-order differential drive system, as well as a physically simulated Segway robot. The results show that the proposed integration of learning and planning can produce higher quality paths than sampling-based kinodynamic planning with random controls in fewer iterations and computation time.
翻译:本文的目的是提高基于取样的心血管动力学规划者在车辆导航方面的道路质量和计算效率,它提出了一个学习框架,用以在抽样规划者扩大过程中确定有希望的控制措施;鉴于动态模型,对强化学习程序进行离线培训,以便在没有障碍的情况下返回低成本控制,在没有障碍的情况下达到当地目标状态(即路标点);通过侧重于系统的动态和不了解环境,这个程序是数据效率高的,并且为机器人系统一次性运行一次;这样,就可以在不同环境中再利用。规划者以知情的方式为学习的控制者创建在线本地目标状态,以便以探索、随机的方式连续偏向目标;对于知情扩展,则通过下列途径生成本地目标状态:(a) 环境障碍环境中的介质轴信息,或(b) 用于具有可移动性成本的设置的波端信息。学习过程和由此产生的规划框架被评估为一级和二级差异驱动系统,以及一个实际模拟Segway机器人。结果显示,拟议的学习和规划方法的一体化和升级路径与升级的逻辑路段,可以产生比模拟更高级的顺序。