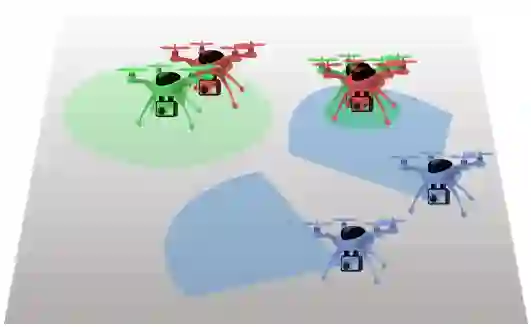
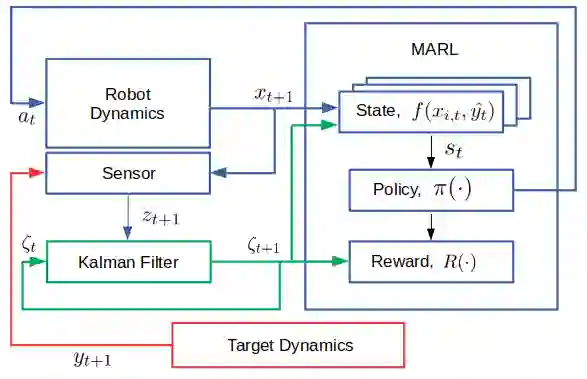
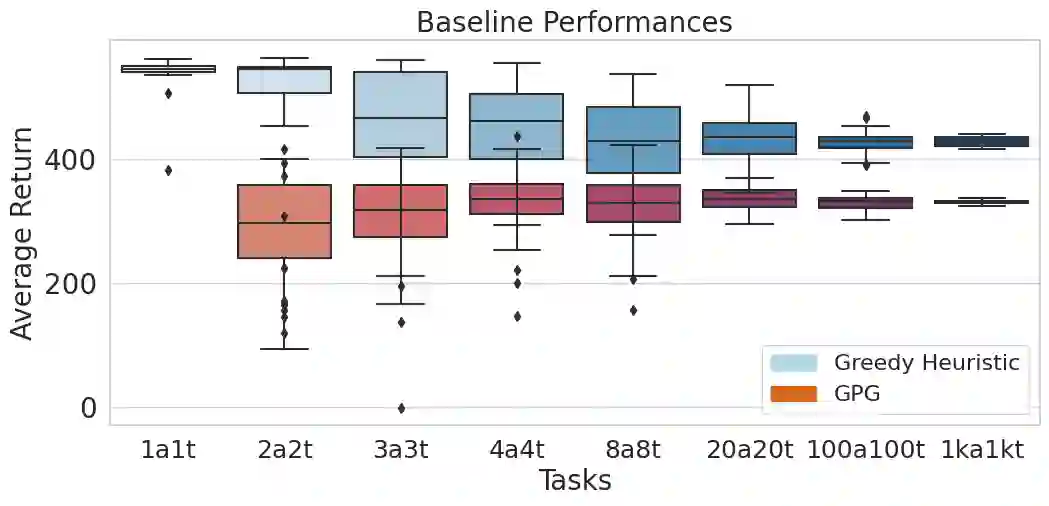
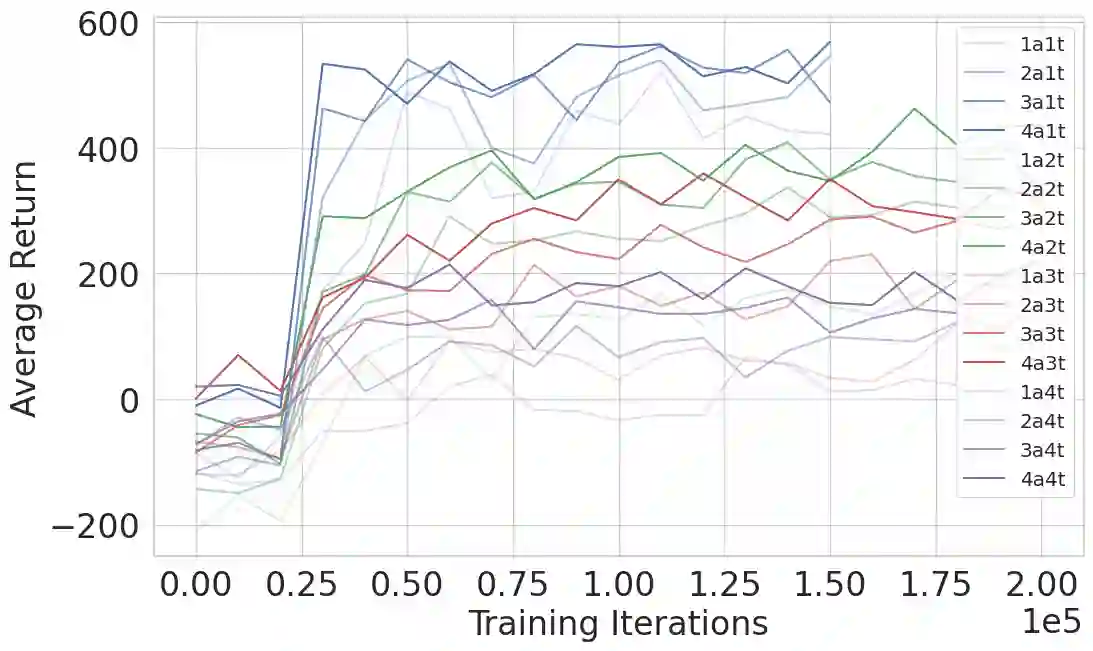
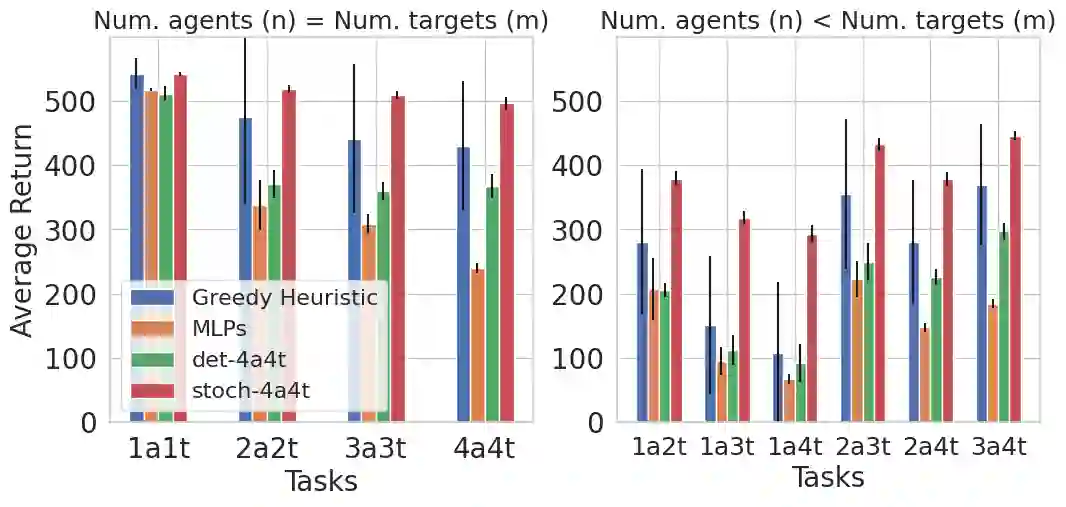
We develop a Multi-Agent Reinforcement Learning (MARL) method to learn scalable control policies for target tracking. Our method can handle an arbitrary number of pursuers and targets; we show results for tasks consisting up to 1000 pursuers tracking 1000 targets. We use a decentralized, partially-observable Markov Decision Process framework to model pursuers as agents receiving partial observations (range and bearing) about targets which move using fixed, unknown policies. An attention mechanism is used to parameterize the value function of the agents; this mechanism allows us to handle an arbitrary number of targets. Entropy-regularized off-policy RL methods are used to train a stochastic policy, and we discuss how it enables a hedging behavior between pursuers that leads to a weak form of cooperation in spite of completely decentralized control execution. We further develop a masking heuristic that allows training on smaller problems with few pursuers-targets and execution on much larger problems. Thorough simulation experiments, ablation studies, and comparisons to state of the art algorithms are performed to study the scalability of the approach and robustness of performance to varying numbers of agents and targets.
翻译:我们开发了一个多机构强化学习(MARL)方法,以学习可扩展的控制政策,进行目标跟踪。我们的方法可以处理任意数量的追逐者和目标;我们展示由多达1000个追逐者组成的任务的结果,追踪1000个目标。我们使用一个分散的、部分可观测的Markov决定程序框架,模拟追赶者,作为接受部分观察(范围及影响)使用固定的、未知的政策移动目标的代理人。我们使用关注机制,将代理人的价值功能参数化;这个机制使我们能够处理任意数量的目标。我们使用渗透性常规的脱离政策的RL方法来训练一项随机的政策,我们讨论它如何使追赶者之间的对冲行为导致一种薄弱的合作形式,尽管完全分散的控制执行。我们进一步开发了一种遮盖性,以便能够在很少追击者目标的较小问题上进行培训,并在大得多的问题上执行。正在进行索拉夫模拟实验、通货膨胀研究和对艺术算法状况的比较,以研究方法和表现的稳健性是否适合不同数目的代理人和目标。