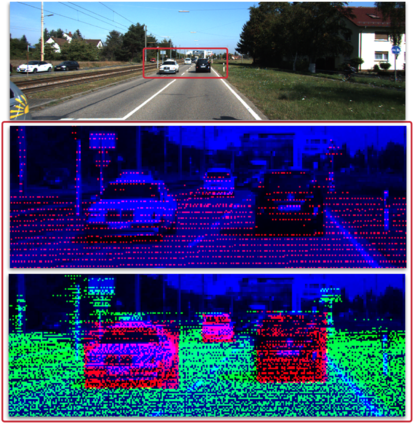
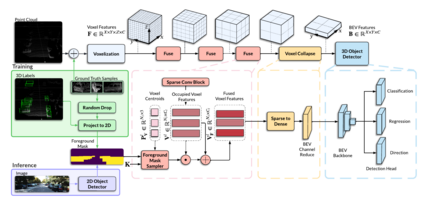
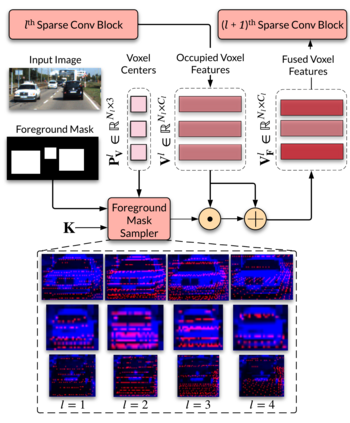
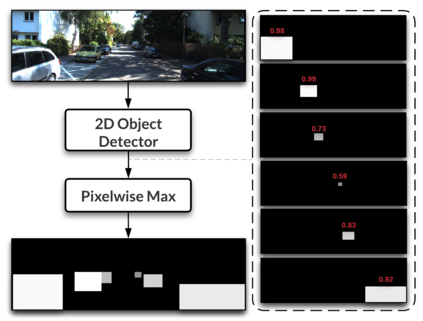
Camera and LiDAR sensor modalities provide complementary appearance and geometric information useful for detecting 3D objects for autonomous vehicle applications. However, current end-to-end fusion methods are challenging to train and underperform state-of-the-art LiDAR-only detectors. Sequential fusion methods suffer from a limited number of pixel and point correspondences due to point cloud sparsity, or their performance is strictly capped by the detections of one of the modalities. Our proposed solution, Dense Voxel Fusion (DVF) is a sequential fusion method that generates multi-scale dense voxel feature representations, improving expressiveness in low point density regions. To enhance multi-modal learning, we train directly with projected ground truth 3D bounding box labels, avoiding noisy, detector-specific 2D predictions. Both DVF and the multi-modal training approach can be applied to any voxel-based LiDAR backbone. DVF ranks 3rd among published fusion methods on KITTI 3D car detection benchmark without introducing additional trainable parameters, nor requiring stereo images or dense depth labels. In addition, DVF significantly improves 3D vehicle detection performance of voxel-based methods on the Waymo Open Dataset.
翻译:相机和LIDAR传感器模式为自动车辆应用探测三维物体提供了互补的外观和几何信息,然而,目前端到端的聚变方法对于培训和低于最先进的激光雷达专用探测器具有挑战性。由于点云宽度,序列聚变方法受到数量有限的像素和点对应物的影响,或者其性能因一种模式的探测而严格封顶。我们提议的解决方案Dense Voxel Fusion(DVF)是一种连续聚变方法,在低点密度区域产生多尺度的密集氧化物特征显示,提高显性。为了加强多式学习,我们直接培训时使用预测的地面真相3D捆绑框标签,避免噪音、探测器特定2D的预测。DVF和多模式培训方法都可以适用于任何基于oxel LDAR 的脊柱。DVF在KITTI 3D 汽车探测基准上公布的聚变方法中排名第3级,而无需引入额外的可训练参数,也不需要立体图像或更深深度的车辆性能。