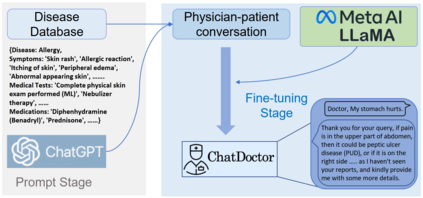
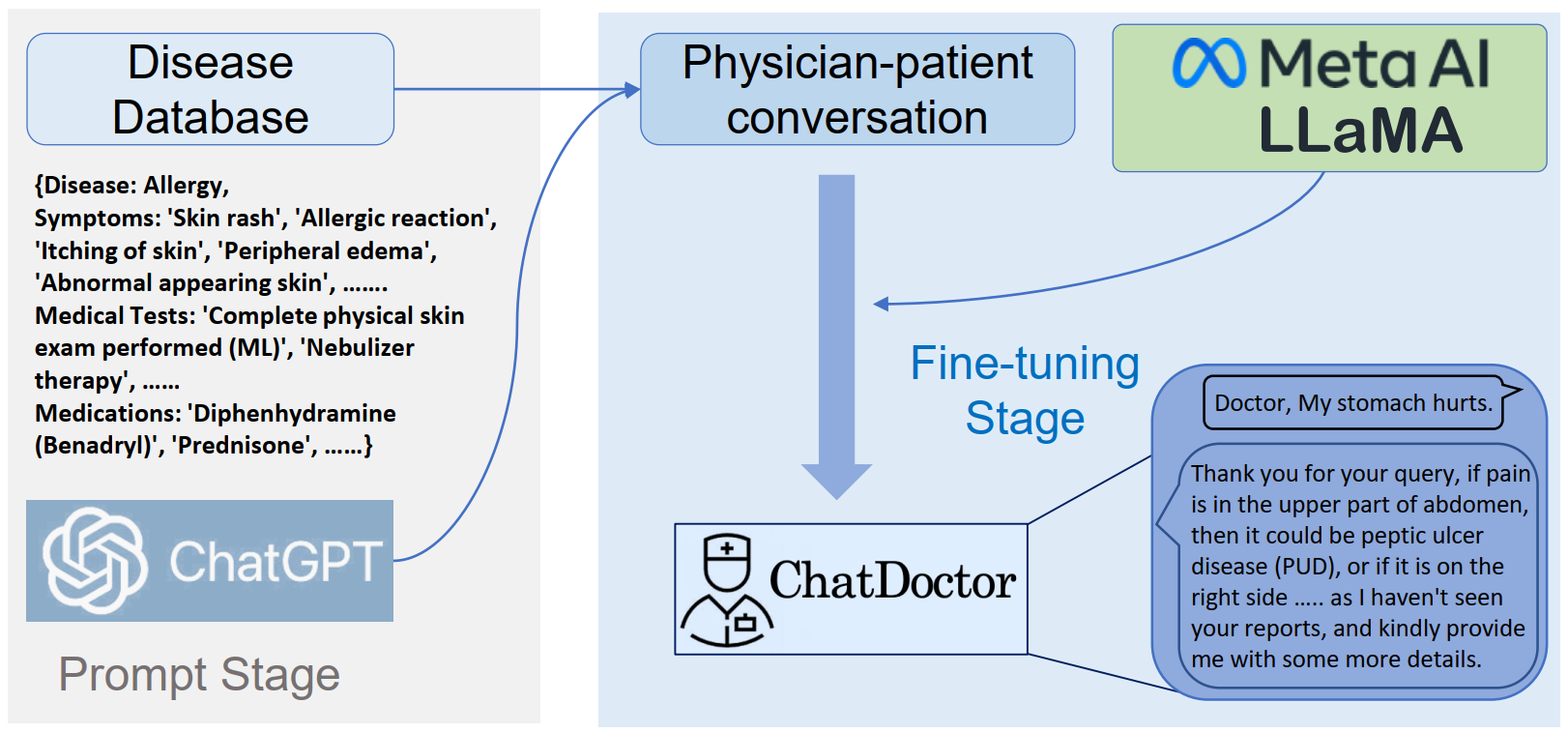
Recent large language models (LLMs) in the general domain, such as ChatGPT, have shown remarkable success in following instructions and producing human-like responses. However, such language models have not been tailored to the medical domain, resulting in poor answer accuracy and inability to give plausible recommendations for medical diagnosis, medications, etc. To address this issue, we collected more than 700 diseases and their corresponding symptoms, required medical tests, and recommended medications, from which we generated 5K doctor-patient conversations. By fine-tuning LLMs using these tailored doctor-patient conversations, the resulting models emerge with great potential to understand patients' needs, provide informed advice, and offer valuable assistance in a variety of medical-related fields. The integration of these advanced language models into healthcare can revolutionize the way healthcare professionals and patients communicate, ultimately improving the overall efficiency and quality of patient care and outcomes. In addition, we made public all the source codes, datasets, and model weights to facilitate the further development of dialogue models in the medical field. The training data, codes, and weights of this project are available at: https://github.com/Kent0n-Li/ChatDoctor.
翻译:----
近期的大语言模型(LLMs)在通用领域,如ChatGPT,在遵循指令并产生类人回复方面表现出了非凡的成功。然而,这种语言模型并没有针对医疗领域进行定制,导致了答案准确度低下和无法提供合理的医学诊断、药物推荐等建议。为了解决这个问题,我们收集了700多种疾病及其相应的症状、需要的医学检查和推荐的药物,从中生成了5K个医生-患者对话。通过使用这些定制的医生-患者对话Fine-tuning LLMs,得到的模型具有非常强的潜力,可以理解患者的需求,提供权威建议,并在各种医疗相关领域提供有价值的帮助。将这些先进的语言模型整合到医疗保健中,可以彻底改革医疗专业人员和患者的沟通方式,最终提高患者护理和结果的整体效率和质量。此外,我们公开了所有源代码、数据集和模型权重,以便促进医疗领域对话模型的进一步发展。该项目的训练数据,代码和权重可在此处获得:https://github.com/Kent0n-Li/ChatDoctor。