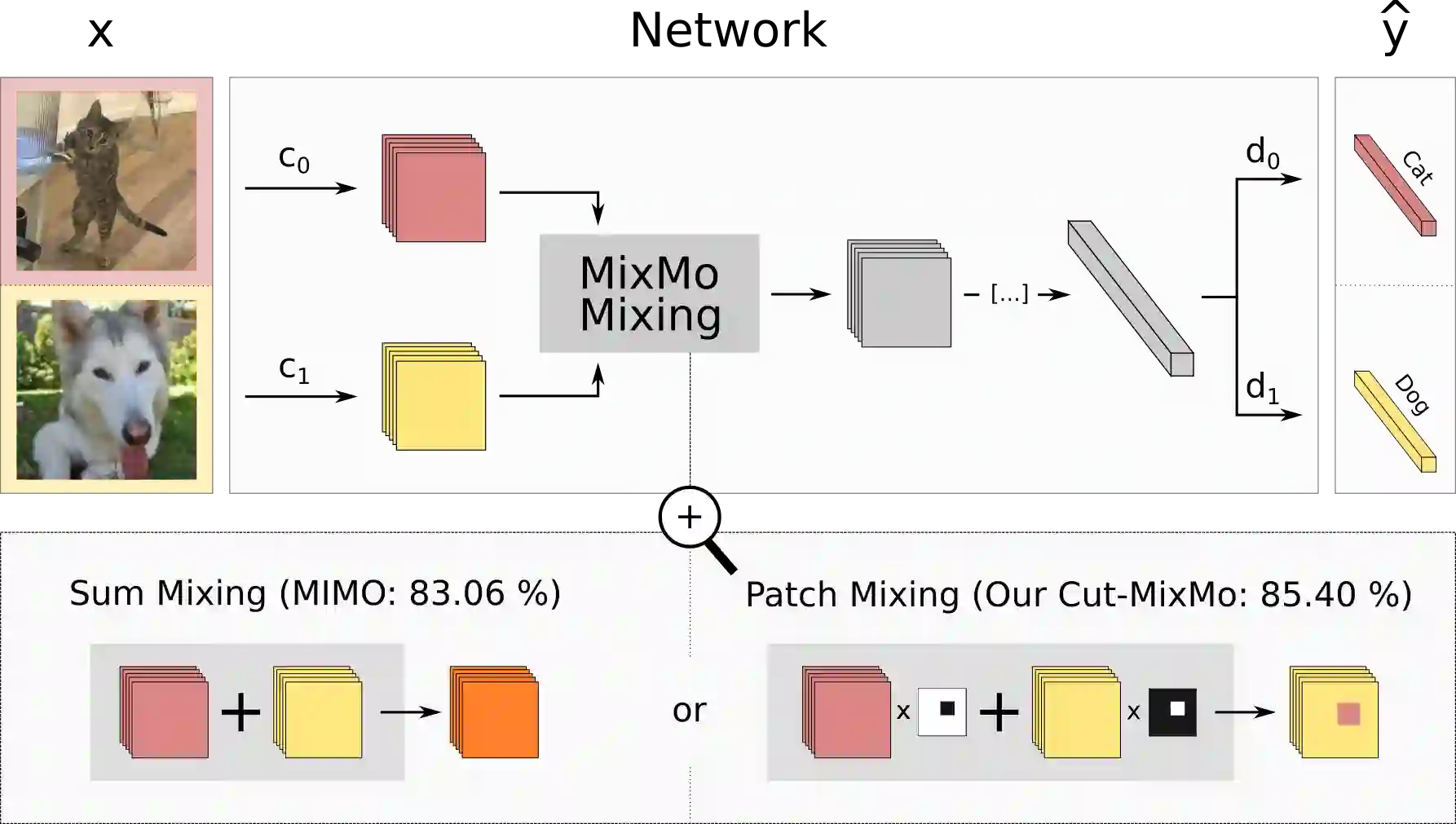
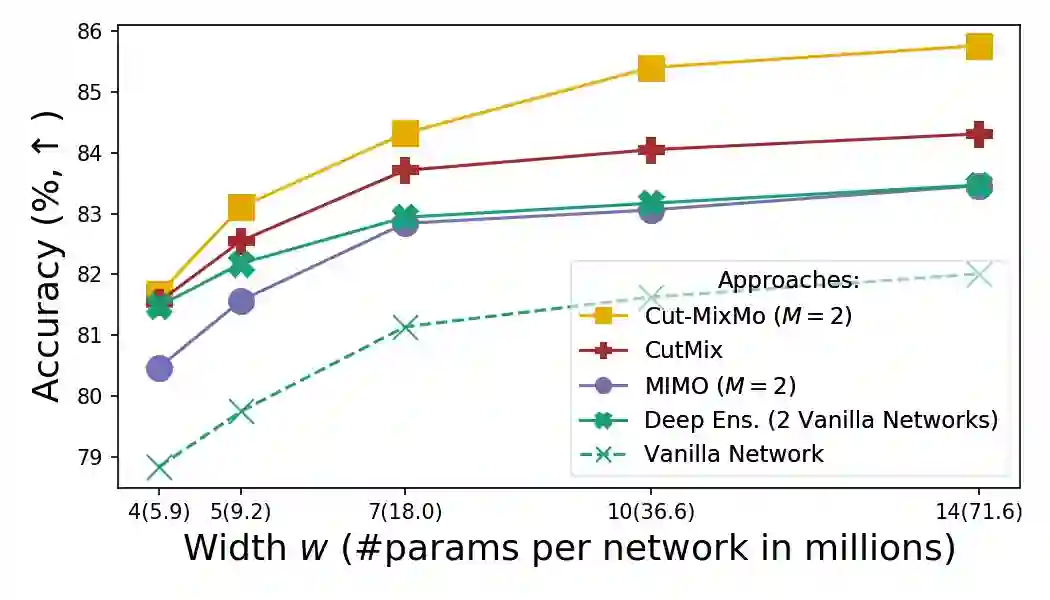
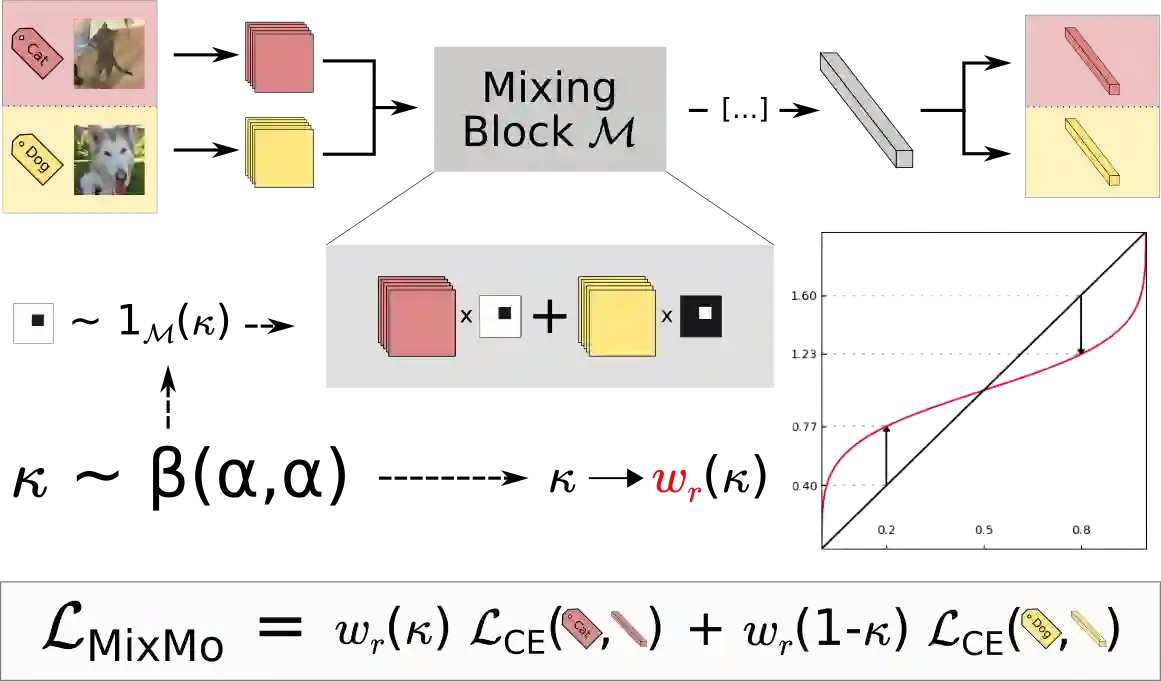
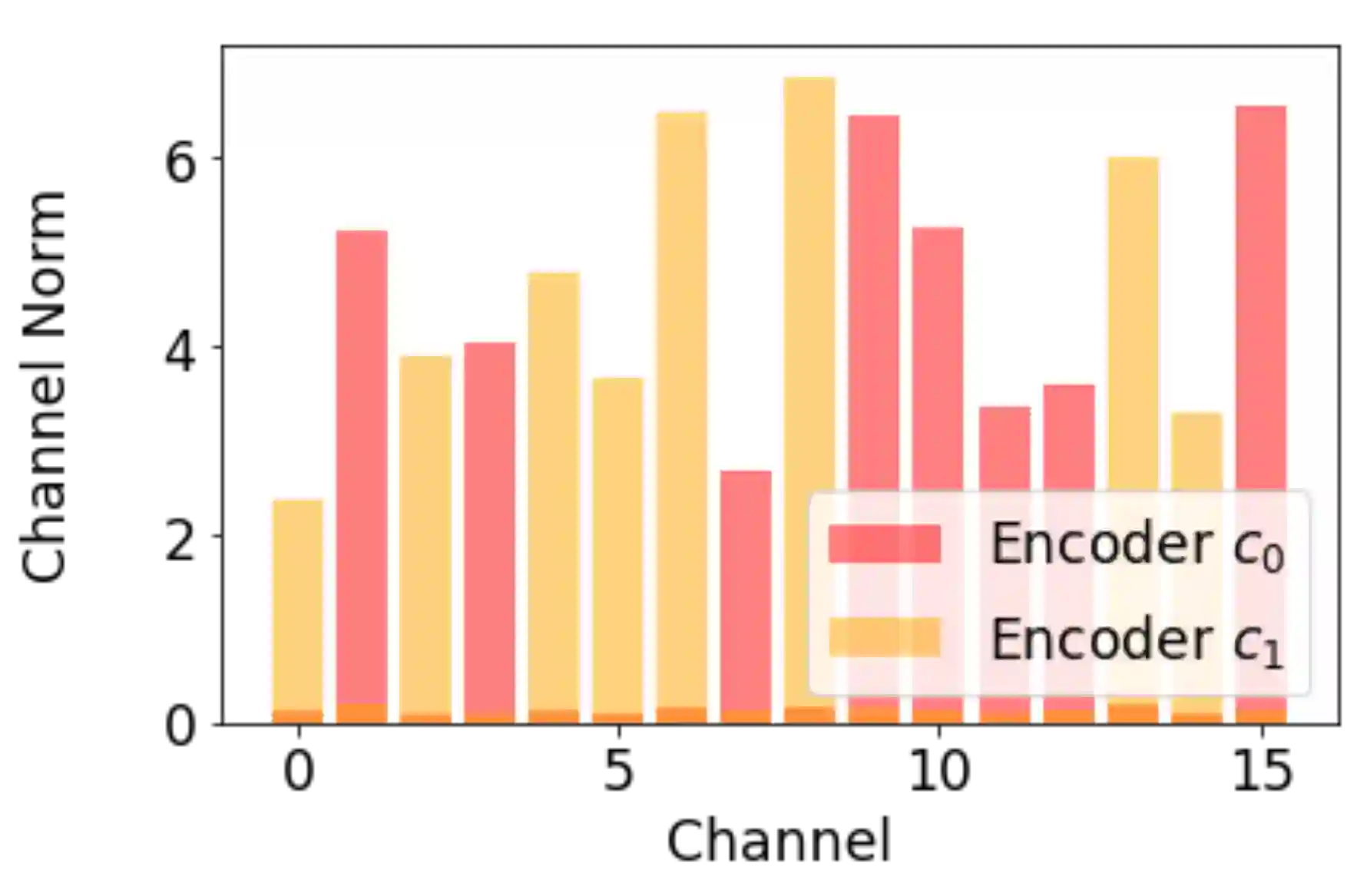
Recent strategies achieved ensembling for free by fitting concurrently diverse subnetworks inside a single base network. The main idea during training is that each subnetwork learns to classify only one of the multiple inputs simultaneously provided. However, the question of how these multiple inputs should be mixed has not been studied yet. In this paper, we introduce MixMo, a new generalized framework for learning multi-input multi-output deep subnetworks. Our key motivation is to replace the suboptimal summing operation hidden in previous approaches by a more appropriate mixing mechanism. For that purpose, we draw inspiration from successful mixed sample data augmentations. We show that binary mixing in features - particularly with patches from CutMix - enhances results by making subnetworks stronger and more diverse. We improve state of the art on the CIFAR-100 and Tiny-ImageNet classification datasets. In addition to being easy to implement and adding no cost at inference, our models outperform much costlier data augmented deep ensembles. We open a new line of research complementary to previous works, as we operate in features and better leverage the expressiveness of large networks.
翻译:通过在单一基网内同时安装不同的子网络而实现的免费的最近战略组合。 培训期间的主要想法是,每个子网络学习只对同时提供的多个输入之一进行分类。 但是,这些多重输入如何混合的问题还没有研究。 在本文中, 我们引入了MixMo, 这是一种学习多投入多输出深度子网络的新的通用框架。 我们的主要动机是用一个更合适的混合机制来取代以前方法中隐藏的次优取精操作。 为此, 我们从成功的混合样本数据增强中汲取灵感。 我们通过使子网络更加强大和更加多样化来显示这些输入的二进制混合( 特别是从 CutMix 的补补丁中) 能够提高结果。 我们改进了 CIRA- 100 和 Tiniy- ImaageNet 分类数据集的艺术状态。 除了容易实施和不增加成本外, 我们的模型比更昂贵的数据更深层的混合机制。 我们打开了与以前工程的新的研究补充线, 因为我们在特性上运行, 并更好地利用大网络的清晰度。