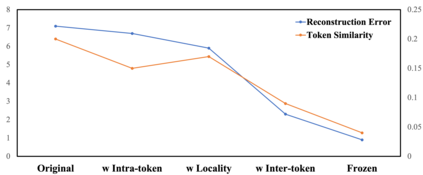
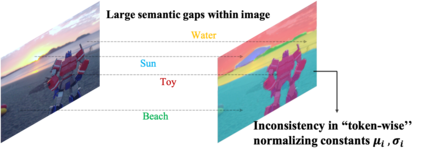
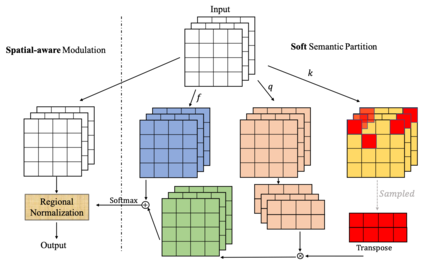
The architecture of transformers, which recently witness booming applications in vision tasks, has pivoted against the widespread convolutional paradigm. Relying on the tokenization process that splits inputs into multiple tokens, transformers are capable of extracting their pairwise relationships using self-attention. While being the stemming building block of transformers, what makes for a good tokenizer has not been well understood in computer vision. In this work, we investigate this uncharted problem from an information trade-off perspective. In addition to unifying and understanding existing structural modifications, our derivation leads to better design strategies for vision tokenizers. The proposed Modulation across Tokens (MoTo) incorporates inter-token modeling capability through normalization. Furthermore, a regularization objective TokenProp is embraced in the standard training regime. Through extensive experiments on various transformer architectures, we observe both improved performance and intriguing properties of these two plug-and-play designs with negligible computational overhead. These observations further indicate the importance of the commonly-omitted designs of tokenizers in vision transformer.
翻译:变压器的结构最近目睹了在视觉任务中应用的蓬勃发展,它与广泛的革命范式形成对照。依靠将投入分成多个象征物的象征化过程,变压器能够利用自我注意来提取其对称关系。虽然变压器的积聚体,但是在计算机的视觉中并没有很好地理解到什么是好的代谢器。在这项工作中,我们从信息权衡的角度来调查这个未经探索的问题。除了统一和理解现有的结构修改之外,我们的衍生还导致更好的视觉代币器设计战略。拟议的调控器(MoToto)通过正常化将内接型能力纳入。此外,标准化的训练制度包含了一个正规化目标托肯普。通过对各种变压器结构的广泛实验,我们观察到这两个插件和玩耍设计的性能得到了改善,计算管理器微不足道。这些观察还进一步表明,在视觉变压器中常见的代币器设计的重要性。