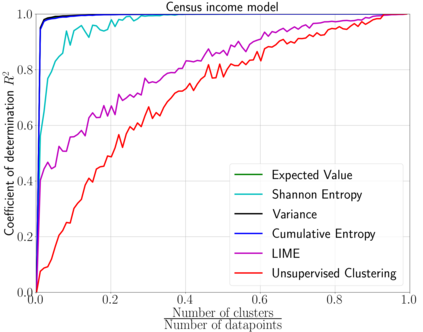
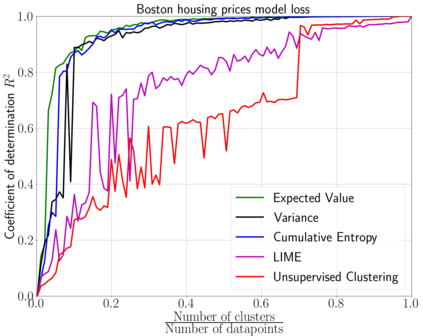
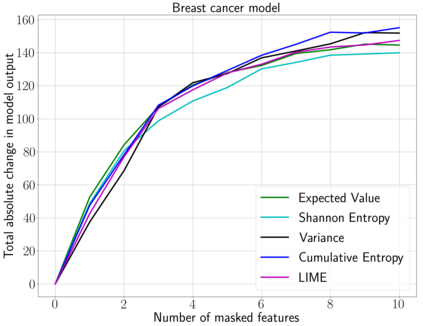
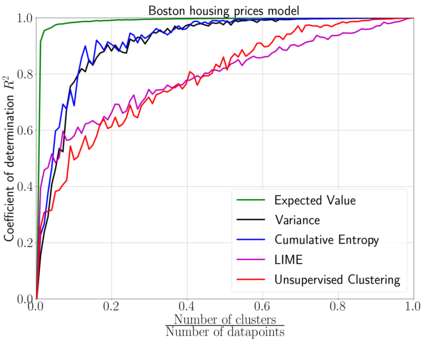
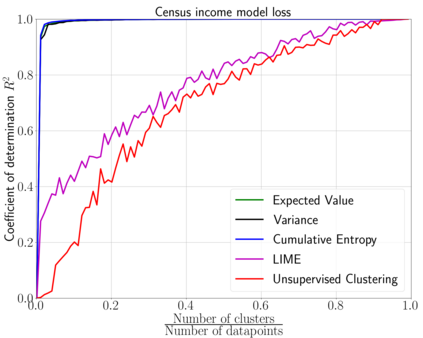
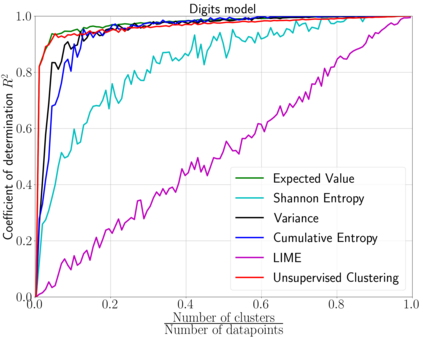
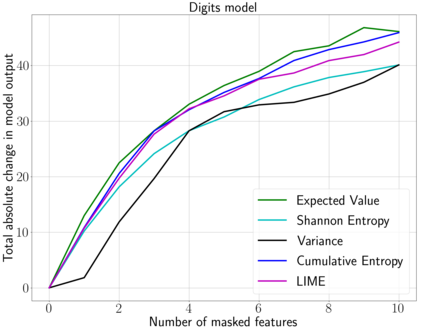
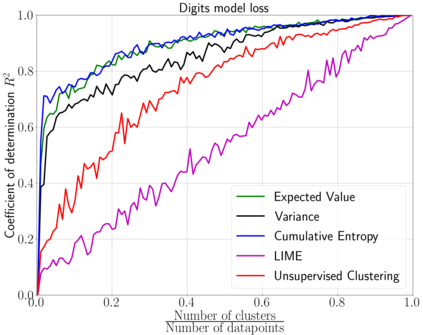
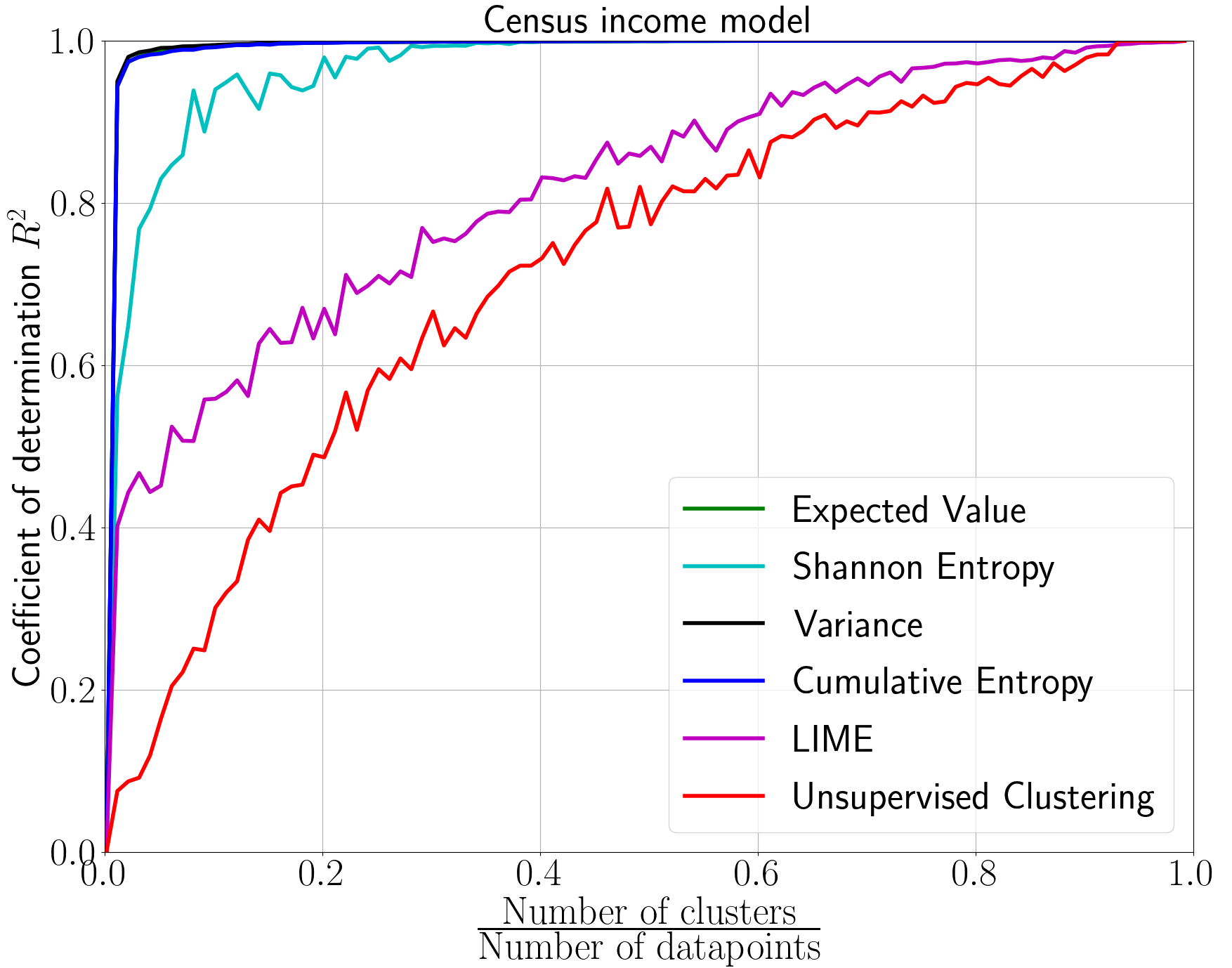
We emphasize the importance of asking the right question when interpreting the decisions of a learning model. We discuss a natural extension of the theoretical machinery from Janzing et. al. 2020, which answers the question "Why did my model predict a person has cancer?" for answering a more involved question, "What caused my model to predict a person has cancer?" While the former quantifies the direct effects of variables on the model, the latter also accounts for indirect effects, thereby providing meaningful insights wherever human beings can reason in terms of cause and effect. We propose three broad categories for interpretations: observational, model-specific and causal each of which are significant in their own right. Furthermore, this paper quantifies feature relevance by weaving different natures of interpretations together with different measures as characteristic functions for Shapley symmetrization. Besides the widely used expected value of the model, we also discuss measures of statistical uncertainty and dispersion as informative candidates, and their merits in generating explanations for each data point, some of which are used in this context for the first time. These measures are not only useful for studying the influence of variables on the model output, but also on the predictive performance of the model, and for that we propose relevant characteristic functions that are also used for the first time.
翻译:我们强调在解释学习模式决定时提出正确问题的重要性。我们讨论了Janzing等人2020年的理论机制自然延伸问题,其中回答了“为什么我的模型预测一个人有癌症?” 回答一个更涉及的问题,即“为什么我的模型预测一个人有癌症?” 回答一个更涉及的问题,“为什么我的模型预测一个人有癌症?” 尽管前者量化了模型变量的直接影响,但后者也说明了间接影响,从而在人类从原因和效果角度可以理解的任何地方提供了有意义的洞察力。我们提出了三大解释类别:观察、模型特定和因果,其中每个因素本身都很重要。此外,本文通过编织不同性质的解释和不同计量的特征来量化特征相关性,作为Shapley 相配体化的特性功能。除了广泛使用的模型预期价值外,我们还讨论统计不确定性和分散性作为信息性候选者的衡量标准,以及它们对于解释每个数据点的优点,其中一些数据点首次用于解释。这些措施不仅有助于研究变量对模型产出的影响,而且对于我们使用的特性提出了相关的特性。