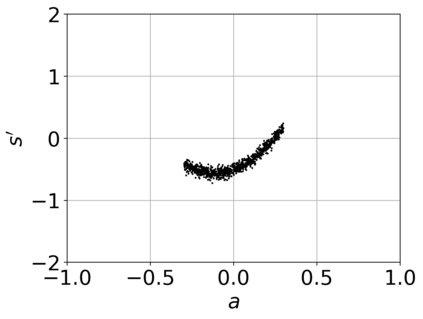
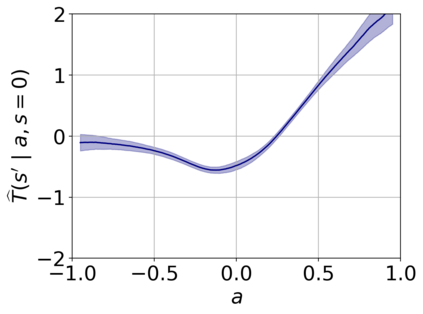
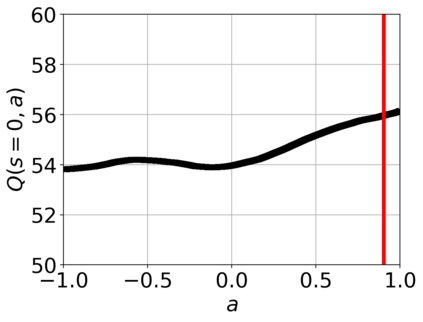
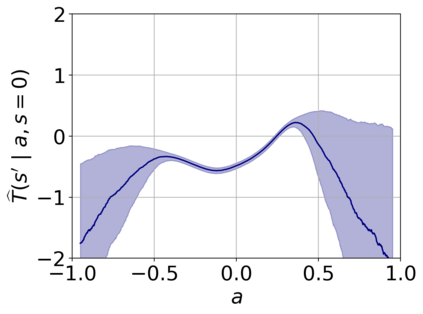
Offline reinforcement learning (RL) aims to find near-optimal policies from logged data without further environment interaction. Model-based algorithms, which learn a model of the environment from the dataset and perform conservative policy optimisation within that model, have emerged as a promising approach to this problem. In this work, we present Robust Adversarial Model-Based Offline RL (RAMBO), a novel approach to model-based offline RL. To achieve conservatism, we formulate the problem as a two-player zero sum game against an adversarial environment model. The model is trained to minimise the value function while still accurately predicting the transitions in the dataset, forcing the policy to act conservatively in areas not covered by the dataset. To approximately solve the two-player game, we alternate between optimising the policy and adversarially optimising the model. The problem formulation that we address is theoretically grounded, resulting in a probably approximately correct (PAC) performance guarantee and a pessimistic value function which lower bounds the value function in the true environment. We evaluate our approach on widely studied offline RL benchmarks, and demonstrate that it outperforms existing state-of-the-art baselines.
翻译:以模型为基础的算法,从数据集中学习环境模型,并在该模型中实行保守的政策优化,这些算法作为解决这一问题的一个很有希望的办法。在这项工作中,我们介绍了基于模型的基于模型的基于模型的基于模型的脱线 RL (RAmbO) 的新办法。为了实现保守主义,我们把问题发展成一个与对抗环境模型的双玩零和游戏。模型经过培训,可以最大限度地减少价值功能,同时仍然准确地预测数据集的转型,迫使该政策在数据集未覆盖的地区采取保守行动。为了大致解决双玩游戏,我们将选择政策与对立地优化模型。我们处理的问题提法是理论上的,结果可能是一种大致正确的(PAC)业绩保证和悲观性价值,从而降低在真实环境中的数值。我们评估了我们的做法,在广泛研究的离线基准值之外,我们评估了现有基准值,并展示了我们所广泛研究的脱线基准值。