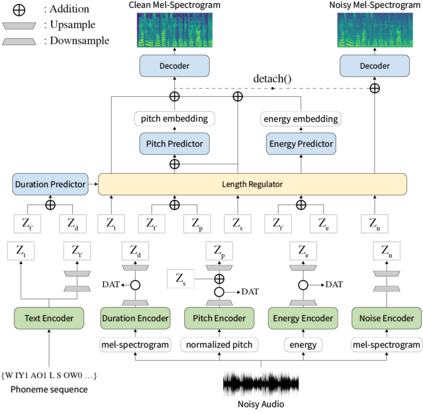
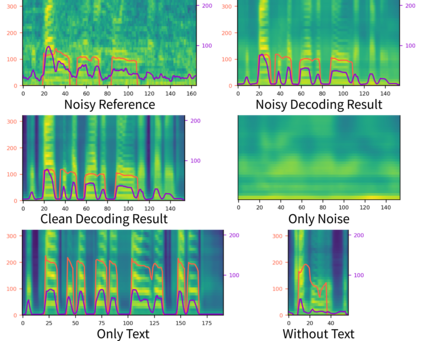
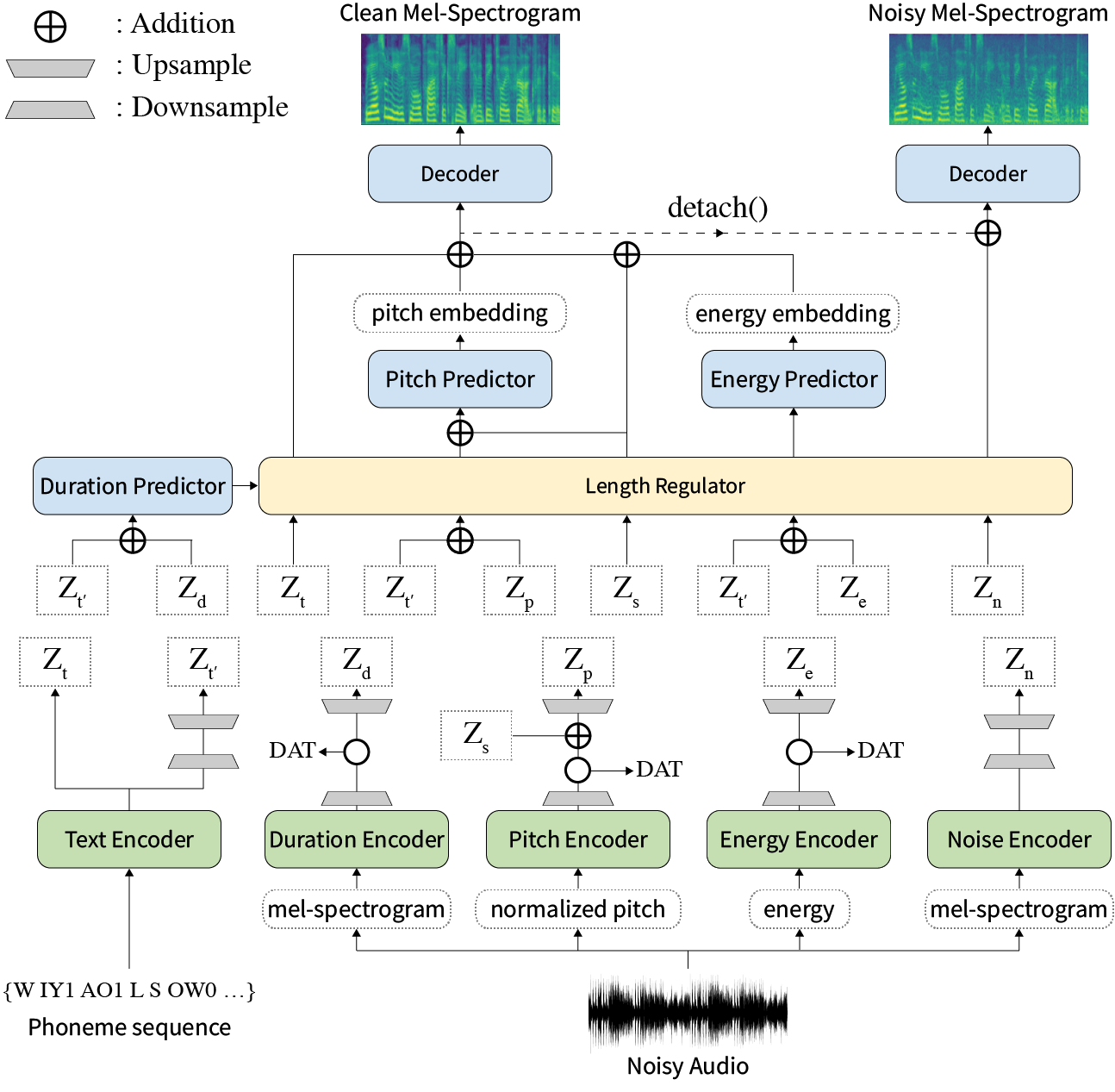
Previous works on neural text-to-speech (TTS) have been tackled on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, none of them has resolved all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable text-to-speech model with robust speech synthesis and high speed. Excluding autoregressive decoding and introducing a novel audio-text aligning method called Mel Calibrator leads speech synthesis more robust on long, unseen data. Disentangled style factor modeling under supervision enlarges the controllability of synthesizing speech with fruitful expressivity. Moreover, our novel noise modeling pipeline using domain adversarial training and Residual Decoding enables noise-robust style transfer, decomposing the noise without any additional label. Our extensive and various experiments demonstrate STYLER's effectiveness in the aspects of speed, robustness, expressiveness, and controllability by comparison with existing neural TTS models and ablation studies. Synthesis samples of our model and experiment results are provided via our demo page.
翻译:先前关于神经文本到声音(TTS)的著作是在培训和推断时间的有限速度、困难合成条件的稳健性、直观性和可控性的基础上处理的。虽然有几种方法解决了某些限制,但没有一种办法同时解决所有弱点。在本文中,我们提出STYLER,这是一个有强力语音合成和高速度的可显示和控制的文本到声音模型。不包括自动递减解解码,并引入一种叫作Mel Calbrator的新型音频文本对齐方法,使语音合成对长期的、不可见的数据更加有力。在监管下分解的风格要素模型扩大了将语言与富有成果的表达性相结合的可控性。此外,我们使用地区性对称培训和余调解调模式的新型噪声建模管道使得噪音-布罗氏风格的传输,在没有任何额外标签的情况下将噪音分解。我们的广泛和多种实验都展示了STYLER在速度、坚固性、直观性和可控性等方面的有效性。通过比较现有的神经TS模型和断层研究,我们模型和实验结果的样本通过演示提供了。